作者: admin
50 Posts
unraid app 插件
最近发现app无法更新
看网上好几个gitee的版本,但是尝试后,下面这个可用
删除空文件夹的linux shell 命令
find -type d -empty | xargs -n 1 rm -rf
按理说find就是递归的,但是测试出一次没有删除完全的case,目标目录中有空格,没有深究,待日后遇到再细究
惠普服务器开启iLO
当你拿到一台新的惠普服务器后,第一重要和有用的任务就是设置iLO。
通过以下的步骤,你将会设置iLO的用户和密码以及相关网络信息
- F9

- 系统配置
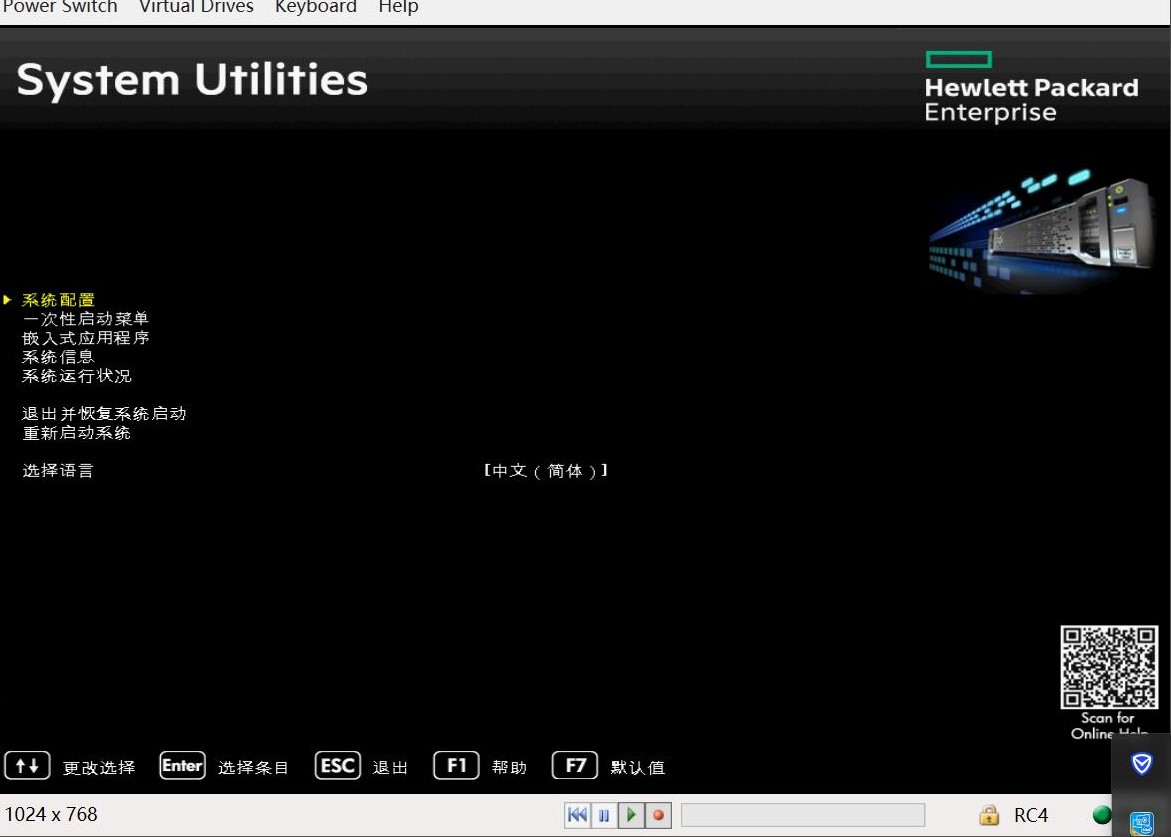
- iLO
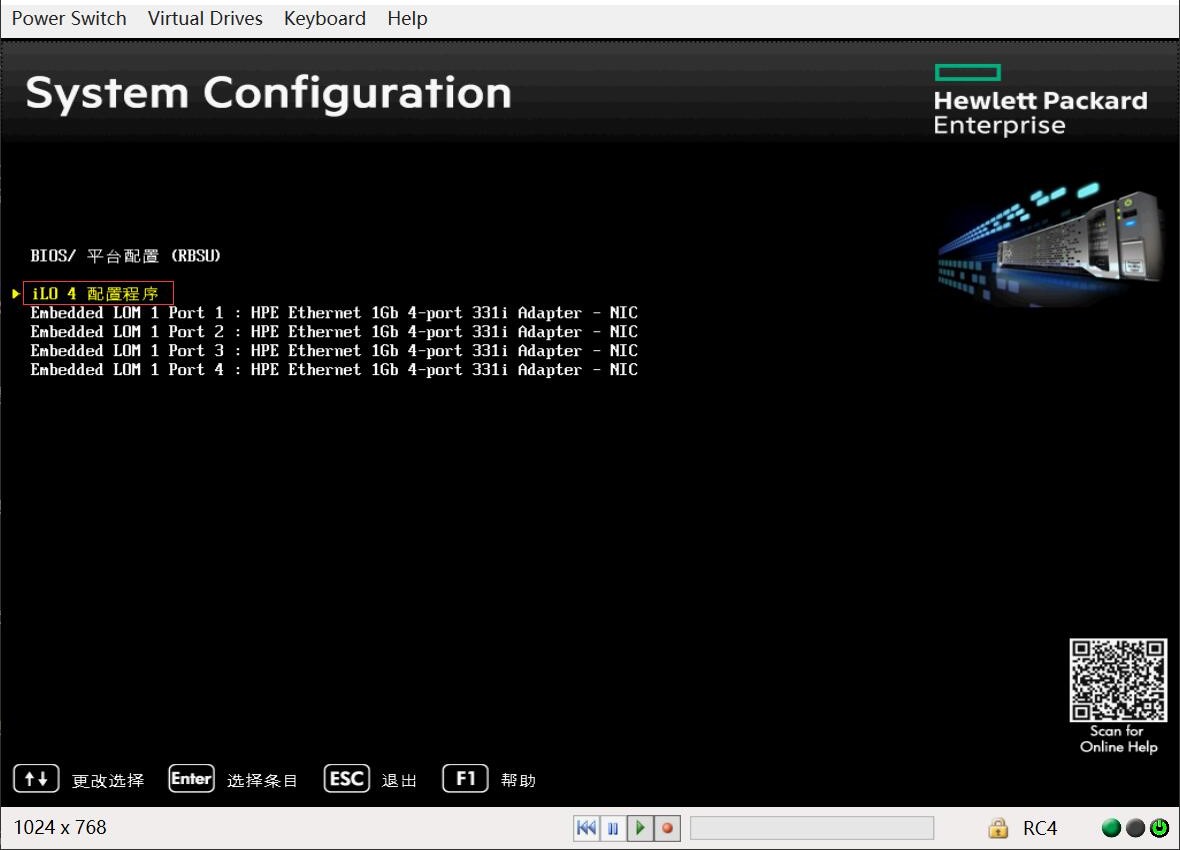
- iLO细节配置
arm-none-eabi-gcc: error: unrecognized command line option ‘-rdynamic’
arm-none-eabi-gcc: error: unrecognized command line option '-rdynamic'
这个是cmake 和 arm-none-eabi-gcc公用的一个问题,本质是cmake跟gcc的兼容性,none-eabi 不支持dynamic 选项。
目前的一个方案就是不要用cmake ,直接用gcc 参数拼接脚本,或者用别的编译框架
微创新:5种微小改变创造伟大产品
总结
- 真正的创新往往是“框架内的”
- 所有创新的阻碍,都是思想“固着”在挡碍。
- 想要真正的创新,必须“不妥协”。
- 创新技能不是天赋,是一种技能,任何人都能通过学习掌握它。
- 只有创意还远远不够。创新行为意味着生成一个新想法之后将其付诸实践。
- 头脑风暴并不像想象的那么有用
- 很多创新是多个创新方法交织的产物
少即是多:减法策略
去除某项功能,创造新的产品
分而治之:除法策略
将某项功能,改变空间形态实现,比如控制面板移除到遥控上,优化产品形态体积。
功能性除法:将某个功能改变其位置
物理型除法:将产品随机分解成若干部分
保留型出发:吧产品缩小
- 桶形高楼
- 剃须刀
- 双面胶
生生不息:乘法策略
- 画中画功能
- 自行车辅助轮
一专多能:任务统筹策略
- 向日葵计划
- 游戏中的图片识别任务
- 生命探测计划的分布式计算机资源
巧妙相关:属性依存策略
- 温度和颜色的关联
- 价格和时间的关系
- 披萨价格和送达时间温度的关系
属性依存策略是在两个先前没有关联的变量之间制造依存关系。
矛盾:创新路上的灯塔
- 每一个矛盾都将为你开辟一条未曾有人涉足的大路,这条路会将你带向一个充满无限可能性的资源宝库。
- 大部分矛盾都是假矛盾,它们存在于我们的思维中,却不是真正的矛盾。
- 许多矛盾事实上都源于观点的不同。通过假定某个矛盾是真矛盾--不管这是某个人的明确看法还是某些人的模糊看法,你都是在禁锢自己的创造力。
- 当你无法完全掌握信息,或是做出了不确定的错误假设时,假矛盾就会出现
- 大部分连接两个对立观点的限定词都是在不确定假设中形成的。它们有时时对的,有时是错的,这完全取决于假设是否准确。由于很多不确定假设都未经任何检验,因此它们中的大多数都是错误假设。这也解释了为什么这些限定词都是矛盾中的弱连结。去掉弱连结,矛盾就不攻自破。
adb 启动某个app的主页面
adb shell dumpsys package [包名]
找android.intent.action.MAIN 的部分
cannot locate symbol “pthread_cond_clockwait”
用ndk做交叉编译时提示如下错误:
cannot locate symbol "pthread_cond_clockwait"
经过多方搜索都无果,最后尝试成功的一种解决方案:
ndk 由25d 降级为21e
api level保持30不变
pixel3 刷机root
-
fasttool 版本不能太高:fastboot version 31.0.3-7562133
-
出厂固件:
https://developers.google.com/android/images?hl=zh-cn
pixel3可以用这个:
https://dl.google.com/dl/android/aosp/blueline-sp1a.210812.016.c1-factory-b41403db.zip?hl=zh-cn -
Magisk-v26.4.apk
注意:
fastboot 时,如果设备驱动不正确,有问号的话,会没有反应:
< waiting for any device >
pixel3需要的驱动:usb_driver_r13-windows.zip
ndk error:executable’s TLS segment is underaligned: alignment is 8, needs to be at least 32 for ARM Bionic
这个是在用ndk交叉编译arm版本时出现的错误。
经过尝试,最终解决方案如下:
api level 太低了,选择30 以上的就可以,例如armv7a-linux-androideabi30-clang
宁静的海
乌苏入梦
出梦衔接
周海媚
乌苏瓶出梦
结束
nginx支持ecc密钥的ciphers
在使用ecc密钥后,网页可能突然提示ciphers 或者protocol相关的错误,那么轻检查 nginx.conf 中的ssl_ciphers字段。
以下的配置支持ecc密钥:
ssl_ciphers EECDH+CHACHA20:EECDH+CHACHA20-draft:EECDH+ECDSA+AES128:EECDH+aRSA+AES128:RSA+AES128:EECDH+ECDSA+AES256:EECDH+aRSA+AES256:RSA+AES256:EECDH+ECDSA+3DES:EECDH+aRSA+3DES:RSA+3DES:!MD5;
ssl_prefer_server_ciphers on;当包含 ssl_ecdh_curve 参数时,一定要重点检测此参数,保证此参数内容跟ecc兼容,或者删掉此参数
曾文正公嘉言钞-书札
p014 复龙翰臣:
二三十年来,士大夫习于优容苟安,揄修袂而养姁步,倡为一种不白不黑不痛不痒之风,建友慷慨感激以鸣不平者,则相与议其后,以为是不更事轻浅而好自见。国藩昔厕六曹,目击此等风味,盖已痛很次骨。
p015 复黄子春:
国藩从宦有年,饱阅京洛风尘,达官贵人优容养望与在下者软熟和同之象,盖己稔知之而惯尝之,积不能平,乃变而为慷慨激烈、轩爽肮脏之一遂,思欲稍易三四十年来不白不黑、不痛不瘁、牢不可破之习,而矫枉过正,或不免流于意气之偏,以是屡蹈愆尤,丛讥取戾,而仁人君予,固不当责以中庸之道,且当怜其有所激而矫之之苦衷也。
--翻译:
我做官有些年头,早就看惯了京师的官场习气,那些达官贵人生活优裕安逸,看重声望;下层的官员则圆滑世故,趋炎附势。这些问题见得多了,我的郁闷也越积越多,心绪久久不能平静,于是变成一种慷慨激烈、嫉恶如仇的性格。我一直希望能够稍稍改变三四十年来这种不白不黑、不痛不痒又牢不可破的积习,但有时候会采取矫枉过正的做法,不免有些意气用事的偏颇,因此屡遭埋怨和指责,招致讥讽和打击,但真正的仁人君子是不会以中庸之道来指责我的,他们应当体谅我这些矫枉过正的做法是有苦衷的。
p016 复石樵:
苍苍者究竟未知何若,吾辈竭力为之,成败不复计耳。
<复褚一帆>
愚民无知,于素所未见未闻之事,辄疑其难于上天。一人告退,百人附和,其实并无真知灼见;假令一人称好,即千人同声称好矣。
p017
<与刘霞仙>
虹贯荆卿之心,而见着以为淫氛而薄之;碧化苌宏之血,而览者以为顽石而弃之。古今同慨,我岂伊殊?屈累之所以一沉,而万世不复返顾者,良有以也。
p018
<与罗罗山、刘霞山>
时事愈艰,则挽回之道,自须先之以戒惧惕厉。傲兀郁积之气,足以肩仁艰巨,然视事太易,亦是一弊。
<致罗罗山>
凡善弈者,每于棋危劫急之时,一面自救,一面破敌,往往因病成妍,转败为功。善用兵者亦然。
p019
<与李次青>
急于求效,杂以浮情客气,则或泰山当前而不克己。以瓦注者巧,以钩注者惮,以黄金注者昏。外重而内轻,其为蔽也久矣。
《于李次青》
锐气暗损,最为兵家所忌。用兵无他谬巧,常存有余不尽之气而已。
p020
《与罗伯宜》
日中者昃,月盈则亏,故古诗“花未全开月未明”之句,君子以为知道。自仆行军以来,每介疑胜疑败之际,战兢恐惧,上下怵惕者,其后恒得大胜;或当志得意满之侯,狃于屡胜,将卒矜慢,其后常有意外之失。(启超按:处一切境遇皆如此,岂惟用兵?)
p021
《与刘霞仙》
欲学为文,当扫荡一副旧习,赤地新立。将前次所业荡然若丧其所有,乃始别有一番文境。(启超按:此又不惟学文为然也)
《复李希庵》
吾乡数人均有薄名,尚在中年,正可圣可狂之际;惟当兢兢业业,互相箴规,不特不宜自是,并不宜过于奖许,长朋友自是之心。彼此恒以过相砭,以善相养,千里同心,庶不终为小人之归。
复刘霞仙
练勇之道,必须营官昼夜从事,乃可渐几于熟,如鸡伏卵,如炉炼丹,未宜须臾稍离。(启超按:教育家之于学生及吾人之自行修养,皆当如是。)
vnc:Failed to execute default web browser – input output error
Failed to execute default web browser - input output error
当远程vnc时,可能会出现如上的问题,
原因是使用了root账户登录导致,需要将vnc的默认登录账户改为非root。
需要在vnc client 和vncserver侧同步改动,以非root账户启动vnc server
config tigervnc in arch linux
pacman -Syu tigervnc
如果安装不成功,则需要手动下载安装包,通过 pacman -U xxx 来安装。
安装成功后,通过如下命令运行:
vncserver :1
默认会提示失败,需要继续设置:
- 用 vncpasswd 创建密码,它会将哈希处理之后的密码存储在 ~/.vnc/passwd。
- 编辑 /etc/tigervnc/vncserver.users 来定义用户映射。该文件中定义的每个用户都会拥有对应的端口来运行会话。该文件中的数字对应的是 TCP 端口。默认情况下,:1 是 TCP 端口 5901 (5900+1)。如果需要运行一个并行的服务端,第二个实例可以运行在下一个最大的、未被占用的端口,即 5902 (5900+2)。/etc/tigervnc/vncserver.users文件示例配置如下:
:1=YourUserName
orange zero3 无法进入系统的问题
现象:第一次是好用的,更新后就无法进入系统了,输入密码后,重新回到登录对话框.
解决: lightdm 更换成gdm3. 具体原因不明,应该是lightdm的autologin有bug.
ref:https://askubuntu.com/questions/1231410/cant-log-in-on-ubuntu-20-04
vncserver: The HOME environment variable is not set
解决:
添加runuser 环境:
[Unit]
After=network.service
[Service]
Type=forking
ExecStart=/sbin/runuser -l root -c "/usr/bin/vncserver"
[Install]
WantedBy=multi-user.targetubuntu开机启动脚本
ubuntu开机启动命令或者脚本,常见三种方法:
- rc.local, 基本被废弃,不推荐了
- update-rc.d,手动rc,这个参见 https://www.cnblogs.com/wal1317-59/p/12693309.html
- systemctl,这个是官方推荐的方法,参见 https://goodmemory.cc/systemctl-boot-script/
一些极品app后缀域名
朋友的一些极品域名,以下域名出售,请联系(The following domain names are selling, please contact): 94724211@qq.com
-
hao321.app 导航 或者行业汇聚
-
i00.app 短域名
-
i11.app 短域名
-
i66.app 短域名 理财 保险类
-
i88.app 短域名 理财 保险类
-
petpet.app 派派 智能硬件相关 宠物
-
iiapi.com api汇总站 短域名
-
goodmemory.cc 美好回忆,好记性,good memory
-
zhizu100.com 直租百分百
-
ihuardhub.com 开源,硬件汇集平台
-
superxgaget.com 超级小玩意,新奇好物
-
superxclaw.com 超级龙虾 龙虾
android下的dropbear编译
安卓默认的sshd应为路径权限的问题,无法正常工作,所以我们选用dropbear。
- 项目地址:https://github.com/ubiquiti/dropbear-android.git
- 配置ndk和交叉编译工具链:
diff --git a/build-dropbear-android.sh b/build-dropbear-android.sh
index 15042af..5be67ce 100755
--- a/build-dropbear-android.sh
+++ b/build-dropbear-android.sh
@@ -28,8 +28,9 @@ cd dropbear-$VERSION
echo "Generating required files..."
HOST=arm-linux-androideabi
-COMPILER=${TOOLCHAIN}/bin/arm-linux-androideabi-gcc
-STRIP=${TOOLCHAIN}/bin/arm-linux-androideabi-strip
+TOOLCHAIN=/xxx/android-ndk-r25b/toolchains/llvm/prebuilt/linux-x86_64
+COMPILER=${TOOLCHAIN}/bin/armv7a-linux-androideabi26-clang
+STRIP=${TOOLCHAIN}/bin/llvm-strip
SYSROOT=${TOOLCHAIN}/sysroot
export CC="$COMPILER --sysroot=$SYSROOT"参考:
https://fh0.github.io/%E7%BC%96%E8%AF%91/2021/02/18/android-dropbear.html
systemctl开机运行脚本
通过systemctl开机运行特定脚本。
老生常谈,但是为了下次一步到位,节省几秒时间,还是整理下。
- /usr/lib/systemd/system 下添加xxx.service
[Unit]
After=network.service
[Service]
Type=forking
ExecStart=xxx #为服务的具体运行命令
ExecReload=xxx #为服务的重启命令
ExecStop=xxx #为服务的停止命令
[Install]
WantedBy=multi-user.target- 给服务文件设置必要的权限,比如754。注意你的目标sh也是有对应执行权限的。
- 使能脚本
systemctl daemon-reload
systemctl enable xxx.service
systemctl start xxx.service- 检查是否运行
systemctl is-enabled xxx.service- 其他systemctl 命令
restart
disable
status
list-units --type=service
unraid的encryption key file
当我们在unraid中启用加密文件系统后,每次开机就要输入密码或者使用key file。
那么unraid的 key file 又是什么东西和内容格式呢?
unraid的key file 就是加密密码的纯字符内容,注意文件不要待空换行。
可以用以下命令生成 :
echo -n "password" >keyfile
参考:
https://forums.unraid.net/topic/85495-unraid-newenckey-change-your-drive-encryption-unlock-key/
mac下如何做串口测试
window下的串口工具很多,大名鼎鼎的sscom之类。但是mac下就不是那么丰富了。
工具
https://github.com/Neutree/COMTool/releases/download/v3.2.1/comtool_macos_v3.2.1.dmg
mac 会提示安全风险,这个我们自己评估,承担风险,确认开启:
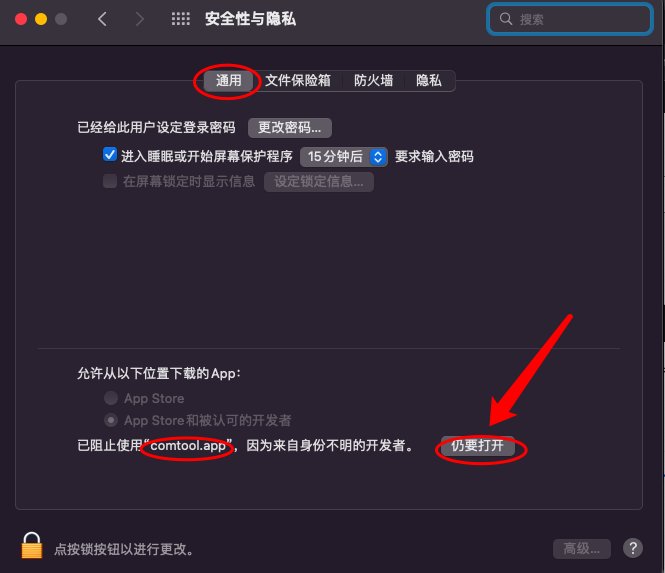
设置串口
适配器连线
这个根据自己实际需要配置。如果只看日志,只收不发,两根线就可以,双向收发就要3线了。

如图所示,蓝色是GND,另一根连接到适配器的rxd上。
选择适配器端口
根据我们使用的适配器,选择设备时会有所不同,要根据实际调整。我们使用的是cp2102是配器:
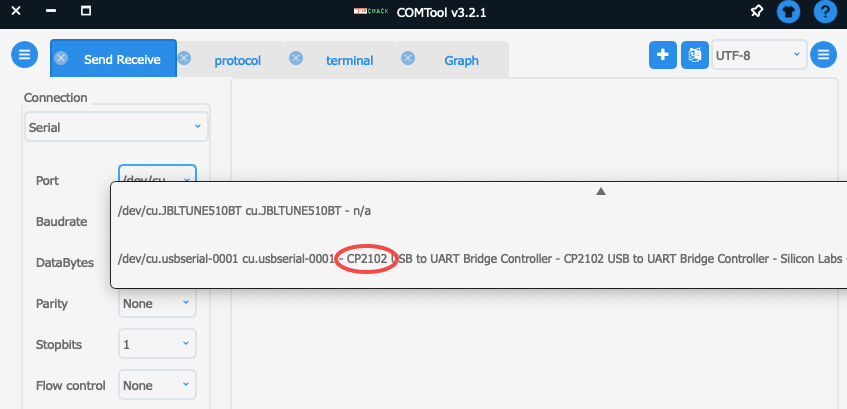
配置串口
根据需要配置波特率和参数就可以,比如我们当前的测试就是921600:
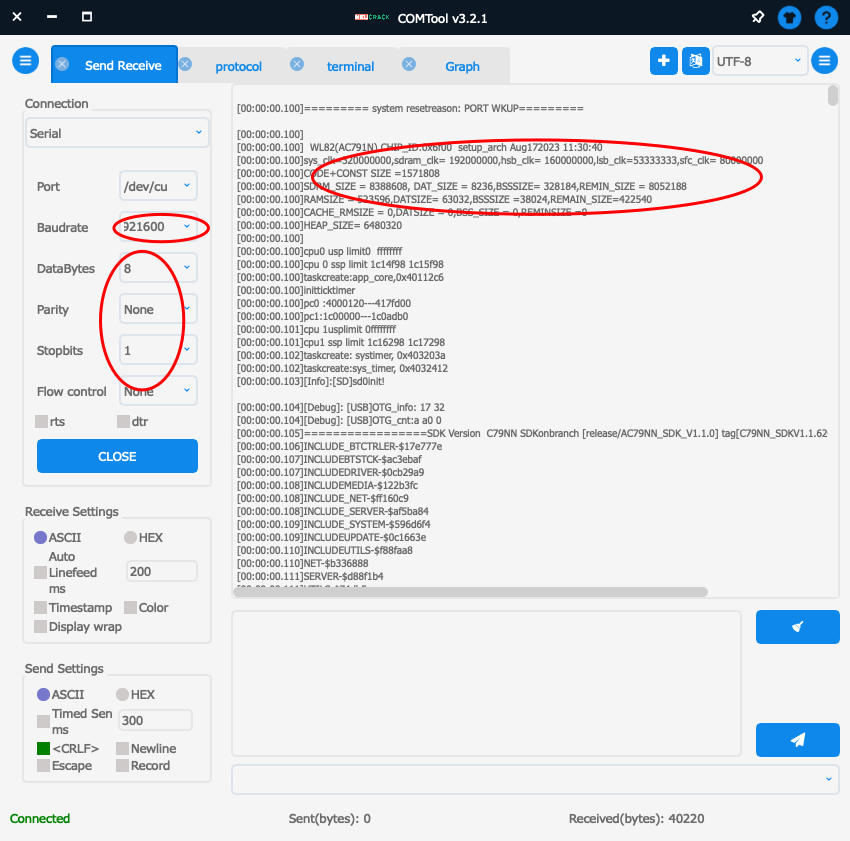
至此,就可以显示日志了,如果你要发送数据,选择正确的连线就可以。
Azure openai 模型部署
模型类型
目前的版本可选的类型如下
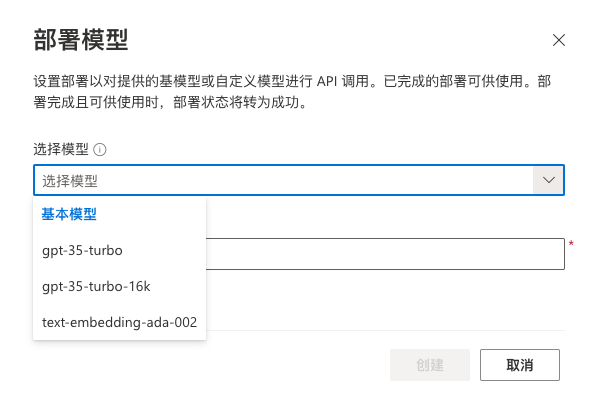
交互速率
每分钟大约720个请求,240K token
ubuntu挂载smb
创建挂载目录
mkdir /media/nas
创建认证文件。若无密码可以忽略这一步。
sudo vim /root/.examplecredentials
按照以下格式写入用户名密码:
username=example_username
password=example_password
为确保安全,同时写入权限限制:
sudo chmod 400 /root/.examplecredentials
安装 cifs
sudo apt install cifs-utils
测试临时挂载。假设挂载服务器是192.168.18.112, 挂载文件夹是 sharedDir。
sudo mount -t cifs -o rw,vers=3.0,credentials=/root/.examplecredentials //192.168.18.112/sharedDir /media/nas
进入挂载目录查看是否正常:
cd /media/nas
设定开机自动挂载
编辑挂载文件:
sudo vim /etc/fstab
在最后面写入如下一行:
//192.168.18.112/share /media/share cifs nofail,vers=3.0,credentials=/root/.examplecredentials
重启查看是否生效。
与刘孟容书札
国藩入世已深,厌阅一种宽厚论说、模棱气象,养成不黑不白不痛不痒之世界,
误人国家已非一日,偶有所触,则轮囷肝胆又与掀振一番。
与王璞山书札
古来名将得士卒之心,盖有在于钱财之外者,
后世将弁专恃粮重饷优为牢笼兵心之具,其本为已浅矣,
是以金多则奋勇蚁附,利尽则冷落兽散。
与彭筱房、曾香海书札
带勇之人,
第一要才勘治民,
第二要不怕死,
第三要不急急名利,
第四要耐受辛苦。
大抵有忠义血性,则四者想从以俱至。
与朱石翘书札
今方民穷财困,吾辈是不能别有噢咻生息之术,
计惟力去害民之人,以听吾民之自孳自活而已。
---现在的情况是,百姓无以为生,国家用度匮乏,我们也不可能有其他的办法让百姓们休养生息,所能做的也只是尽全力清除那些侵害百姓的人,让百姓们能够不受干扰地自己存活下去
复欧阳晓岑书札
集思广益非易事,
要当内持定见而六辔在手,
外广延纳而万流赴壑,
乃为尽善。
--集思广益本来就不是一件容易的事,关键是内心要持有不可动摇的主见,就像手握住套住群马的缰绳驾驭车马,广泛听取不同的意见,如同万条流水奔向沟壑,才能做到尽善尽美。
通过frp访问内网vnc服务
背景
需要远程访问内网linux桌面,而且anydesk等不好用,所以想到通用的vnc方案。但是设置端口映射后,发现依然端口无法访问,怀疑是被协议级检测了,所以想到frp穿透下。
方案
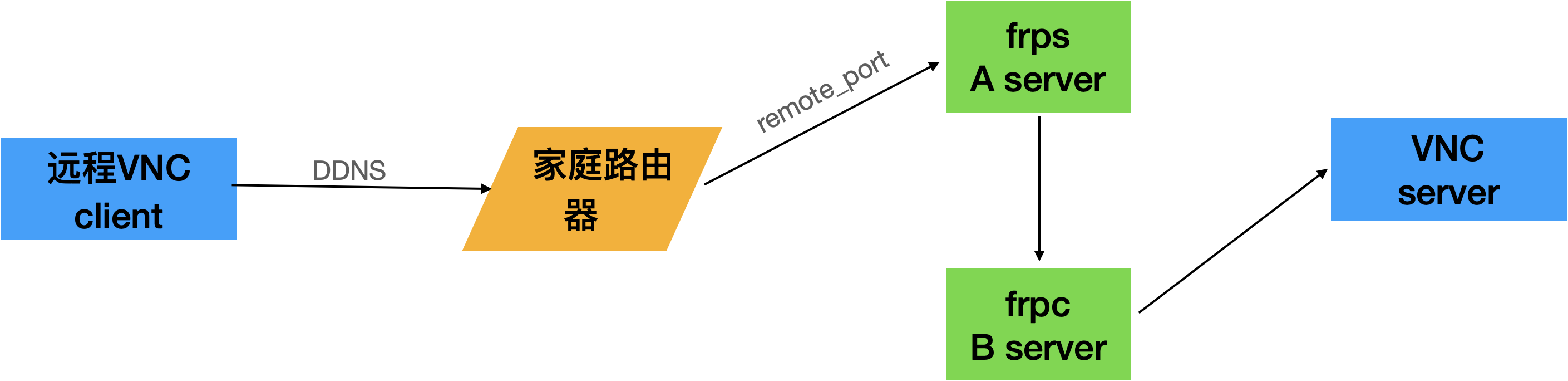
步骤
- 配置要ddns域名和端口映射,否则无法访问到内网主机
- 安装frps 和frpc,根据具体需要,可以是一台物理机,也可以是分开的主机。
配置
frps.ini
[common]
bind_port = 7000frpc.ini
[common]
server_addr = 127.0.0.1
server_port = 7000
[ssh]
type = tcp
remote_port = 6000
local_port = 5900
local_ip = 127.0.0.1注意:此配置表示frpc和vnc server在一个机器,如果不在一个机器,要实际修改local_ip
frp 开机启动
frpc
vim /lib/systemd/system/frpc.service
[Unit]
#服务描述
Description=frp service
After=network.target syslog.target
Wants=network.target
Requires=frps.service
After=frps.service
[Service]
Type=simple
TimeoutStartSec=infinity
ExecStartPre=/bin/sleep 30
#执行命令
ExecStart=/usr/local/frp/frpc -c /usr/local/frp/frpc.ini
[Install]
WantedBy=multi-user.targetsystemctl daemon-reload
#启动
sudo systemctl start frpc
#关闭
sudo systemctl stop frpc
#重启
sudo systemctl restart frpc
#查看状态
sudo systemctl status frpcfrps
与frpc类似
[Unit]
#服务描述
Description=frp service
After=network.target syslog.target
Wants=network.target
Before=frpc.service
[Service]
Type=simple
#执行命令
ExecStart=/usr/local/frp/frps -c /usr/local/frp/frps.ini
[Install]
WantedBy=multi-user.targetdeepin安装sshd vnc
sshd
安装服务
sudo apt install openssh-server
启动服务ssh
sudo systemctl start ssh
设置开机自启动
sudo systemctl enable ssh
x11vnc
与江岷樵、左季高书札
今日百废莫举,千疮并溃,无可收拾,独赖此精忠耿耿之寸衷,与斯民相对于骨岳血渊之中,冀其塞觉横流之人欲,以挽回厌乱之天心,庶几万有一补。
不然,但就局势论之,则滔滔者吾不知其所底也。
复彭丽生书札
无兵不足深忧,无饷不足痛哭,独具目斯世,求一攘利不先、赴义恐后、忠愤耿耿者不可亟得。此其可为浩叹也。
答欧阳功甫书札
人才高下,视其志趣。
卑者安流俗庸陋之规,而日趋污下。
高者慕往哲盛隆之轨,而日即高明。
答黄麓溪书札
耐冷耐苦,耐劳耐闲。
致刘孟容书札
吾辈今日苟有所见,而欲为行远之计,又可不早具坚车乎哉!
解释:
我们今天倘若有所计划,想做传之久远的打算,能不早早的预备坚实的车子(好文章)吗?
复贺耦耕书札
今日而言治术,则莫若综核名实;
今日而言学术,则莫若取笃实践履之士。
物穷则变,救浮华者莫如质。
积翫之后,振之以猛,意在斯乎!
宝塔命令
重置密码:cd /www/server/panel && btpython tools.py panel testpasswd
清除登陆限制:rm -f /www/server/panel/data/*.login
mount开机自动挂载smb路径
root用户编辑/etc/fstab文件,在末尾加入一行:
//ip地址或计算机名/共享文件夹名 挂载点 smbfs username=用户名,password=密码 0 0说明:ubuntu12.10之后,smbfs被cifs代替了,需要:
- sudo apt-get install cifs-utils
- 将上面中的smbfs 换位cifs
从0开玩lichee zero-5-mmc烧录
一般比较小的系统我们用spi flash。 比较大的系统比如debian,我们需要mmc sd卡。
分区
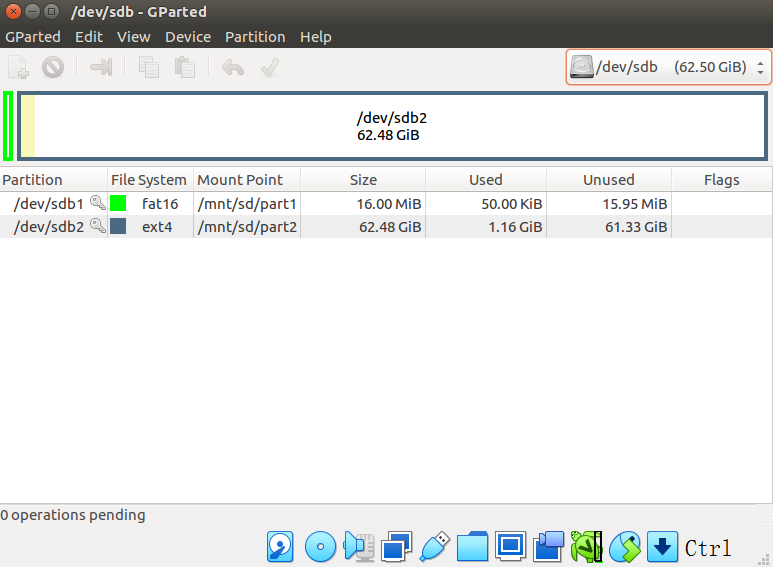
准备
将所需的所有目标文件,都拷贝到当前目录下。
uboot
dd if=u-boot-sunxi-with-spl.bin of=/dev/sdb bs=1024 seek=8
第一分区
cp boot.scr /mnt/sd/part1
cp sun8i-v3s-licheepi-zero-dock.dtb /mnt/sd/part1/
cp zImage /mnt/sd/part1
第二分区
tar vxf rootfs.tar -C /mnt/sd/part2
Journal superblock magic number invalid
原因:
新的操作系统上使用系统自带的 mkfs.ext4 对文件系统进行了格式化,默认会使用一些新的的特性,这些新的特性在旧的系统上是无法使用的,即在旧的内核上不支持。
解决:
tune2fs -l /dev/sdb2
tune2fs -O ^has_journal /dev/sdb2
from: https://blog.csdn.net/p1279030826/article/details/119837695
gparted 要点
你可能会遇到 :The primary GPT table is corrupt, but the backup appears OK
在创建第一个主分区的时候,注意要预留1M空间,否则就会出现上面的corrupt异常:
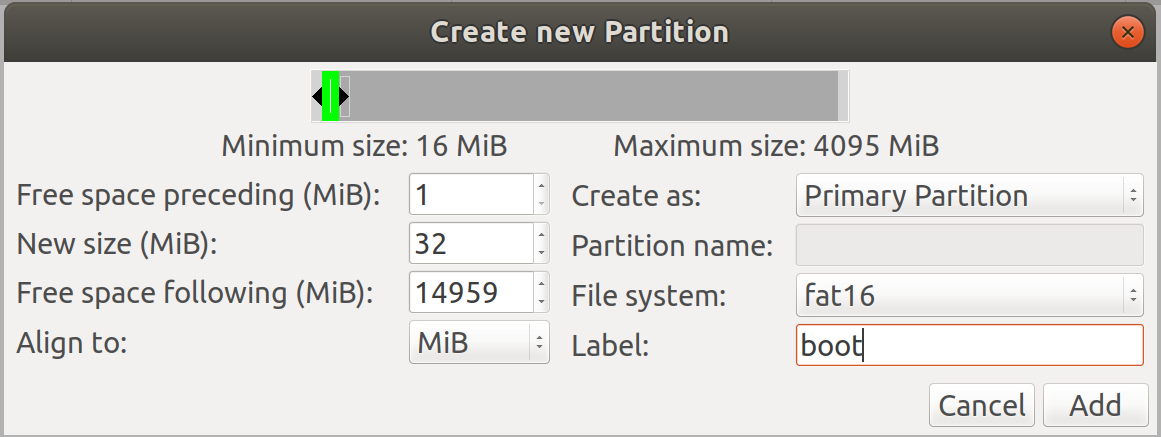
mount: wrong fs type, bad option, bad superblock on
报错:mount: wrong fs type, bad option, bad superblock on
apt-get install nfs-common
mkfs -t ext4 /dev/sdb2
具体参数要根据实际环境微调
virtualbox 共享目录不生效
原因是guest addistions 没生效。
解决:
将virtualbox安装目录下的VBoxGuestAdditions.ios 加载到第一主光驱,然后重启:
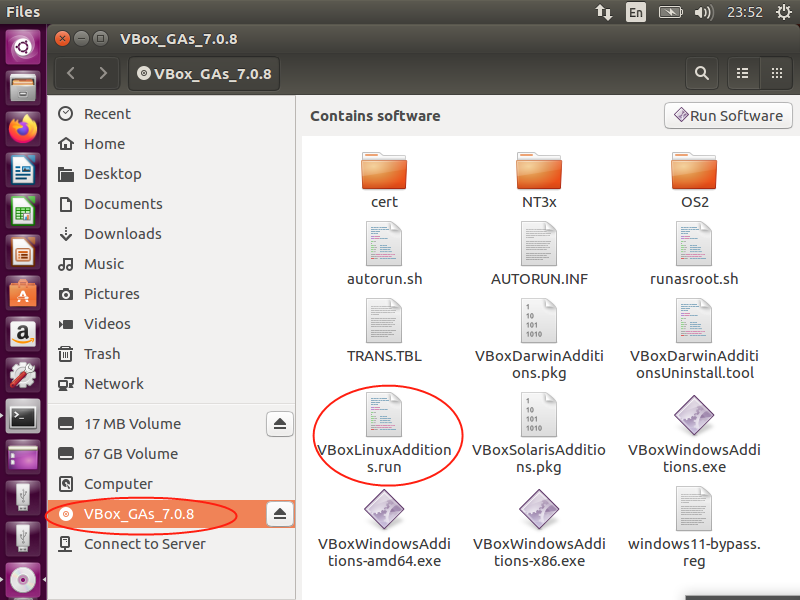
然后运行:
cd /media/xxx/VBox_GAs_7.0.8
sudo shell VboxLinuxAdditions.run
执行完成后,再重新配置共享目录,发现确定是有更新的效果了,再去看挂载目录,就会发发现成功了
virtalbox 无法找到usb sd
安装了virtualbox的ubuntu,也在usb设备中选择了设备,但是就是在ubuntu中无法找到sd:
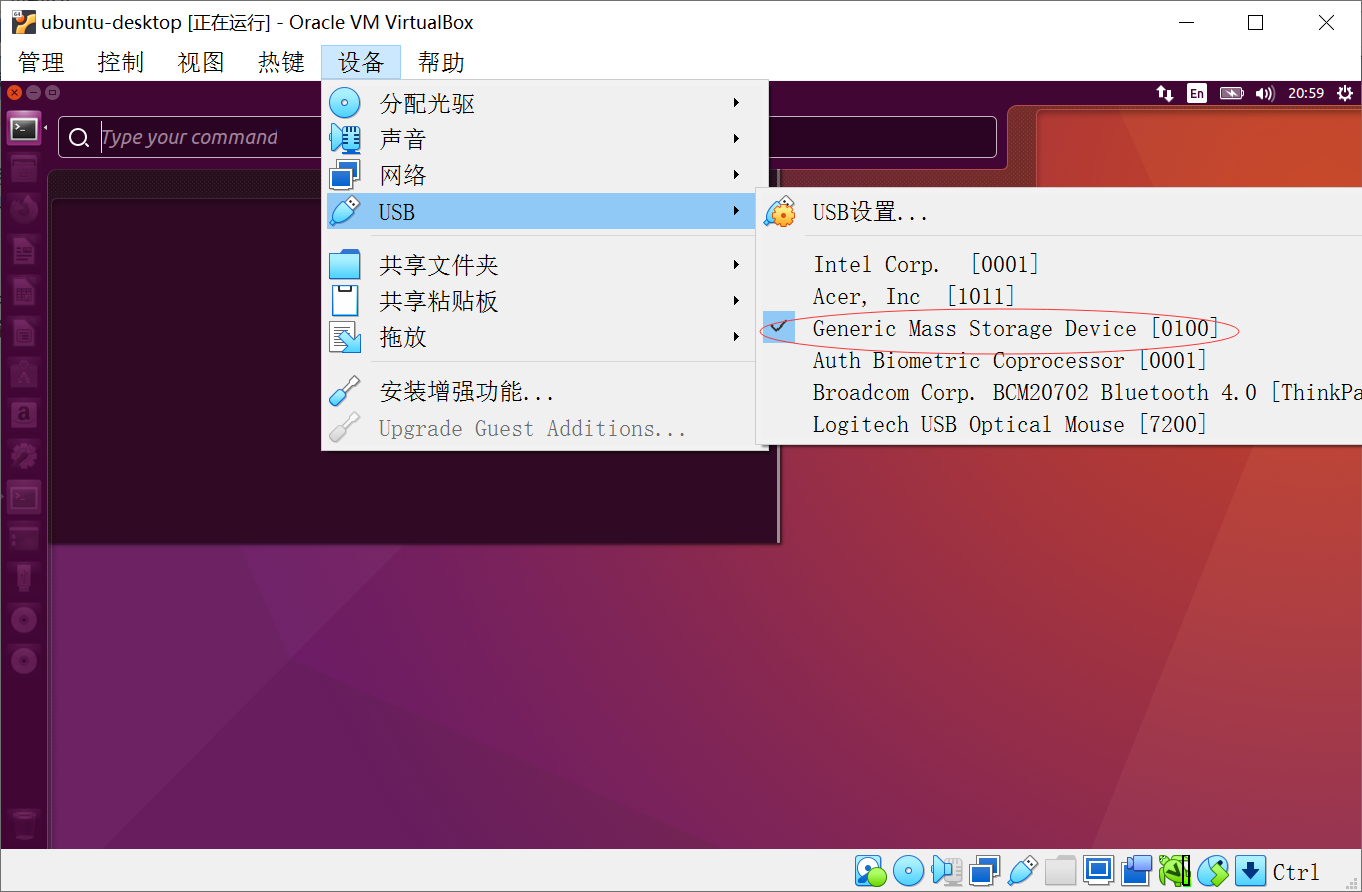
解决:
记得,开启virtual disk后记得重启virtalbox,就可以检测到sd了。
从0开玩lichee zero-3-rootfs编译
build
apt-get install linux-headers-$(uname -r)
wget https://buildroot.org/downloads/buildroot-2017.08.tar.gz
tar xvf buildroot-2017.08.tar.gz
cd buildroot-2017.08/
make menuconfig
make
troubleshoot
- host-m4 版本问题:c-stack.c:55:26: error: missing binary operator before token "("
解决: 由m4-1.4.18升级为m4-1.4.19。修改package/m4下的m4.mk和m4.hash
m4.mk:M4_VERSION = 1.4.19m4.hash:
sha256 63aede5c6d33b6d9b13511cd0be2cac046f2e70fd0a07aa9573a04a82783af96 m4-1.4.19.tar.xz - bison: Please port gnulib fseterr.c to your platform
解决:cd output/build/host-bison-3.0.4sed -i 's/IO_ftrylockfile/IO_EOF_SEEN/' lib/*.c echo "#define _IO_IN_BACKUP 0x100" >> lib/stdio-impl.h - libfakeroot.c:99:40: error: '_STAT_VER' undeclared
#ifndef _STAT_VER #if defined (__aarch64__) #define _STAT_VER 0 #elif defined (__x86_64__) #define _STAT_VER 1 #else #define _STAT_VER 3 #endif #endif