关于github的GITHUB_TOKEN
这两天在研究github的docker托管服务,被GITHUB_TOKEN搞的有点迷糊,以为是一个新的token,经过研究:
- GITHUB_TOKEN只是PAT在action或者workflow中的特指符号语法,并不是一个新的token
- 其有对应成套的符号,比如${{ secrets.GITHUB_TOKEN }} 和${{ secrets.SECRET_NAME }}等,这套实践主要是考虑安全泄密和注入。
这两天在研究github的docker托管服务,被GITHUB_TOKEN搞的有点迷糊,以为是一个新的token,经过研究:
这两天瞎折腾,因为数据库不一致的问题,一气之下把baota image删掉了,很多跟数据库相关的服务都歇了。
宝塔自用,在nas环境配合下数据库,搞个网络环境还是很方便的。
再重新拉取baota镜像时,发现怎么也访问不了,看日志,也没发现什么线索,所以才萌生了自己搞个docker的念头,主要是想定位下问题。
根据官方 www.bt.cn 最新的安装脚本制作了最新的 docker镜像:
https://gitlab.com/hiproz/baota-centos7-docker
docker run -tid --name baota --restart always -v /your-local-dir:/www -p your-local-port:8888 registry.gitlab.com/hiproz/baota-centos7-docker查看 run.log
查看映射路径下的default.txt, 注意要使用实际映射的端口,default.txt显示的是系统内部的端口。
10054是认证的错误,跟本地的git账户信息,token机制等相关。
解决:
git config --global user.name "xxx"
git config --global user.email "xxx"ipconfig /flushdns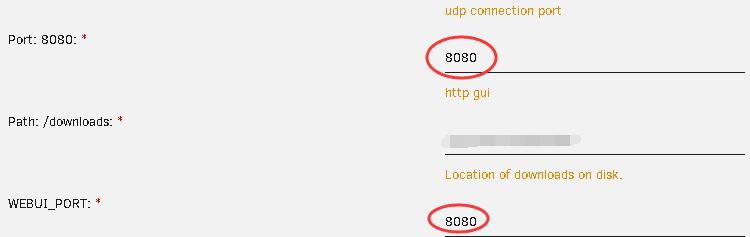
最近在淘宝买了个tplink的ipc玩,买的时候是冲着onvif的,实际测试下,根本是骗人的,不支持onvif,本来想着退掉,后来研究了下,猜出来了rtsp的地址,也就凑合着用了。
在实现了通过rtsp全天录像后,今天想玩下通过HomeaAssistant把摄像头接入苹果homekit. 特将过程整理分享出来,供大家参考。
整个步骤如下:
android_ip_webcam:
- host: 192.168.xx.xxcamera:
- platform: ffmpeg
input: -rtsp_transport tcp -i rtsp://xx:xx@192.168.xx.xx/xx
name: tp-cam

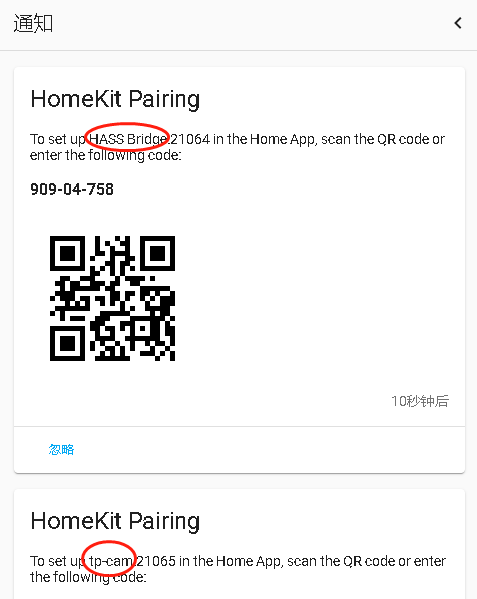
以上就基本完成了通过HA绑定到苹果的目的,但这个时候HA的首页还是空的,如果想在首页展示摄像头,需要点击web页面右上角的 “编辑仪表盘”=》“添加卡片”,自己选择编辑才会出现摄像头的实时视频,刚开始在这一步迟疑了好久,以为配置成功了设备就应该自己出现在HA的首页。
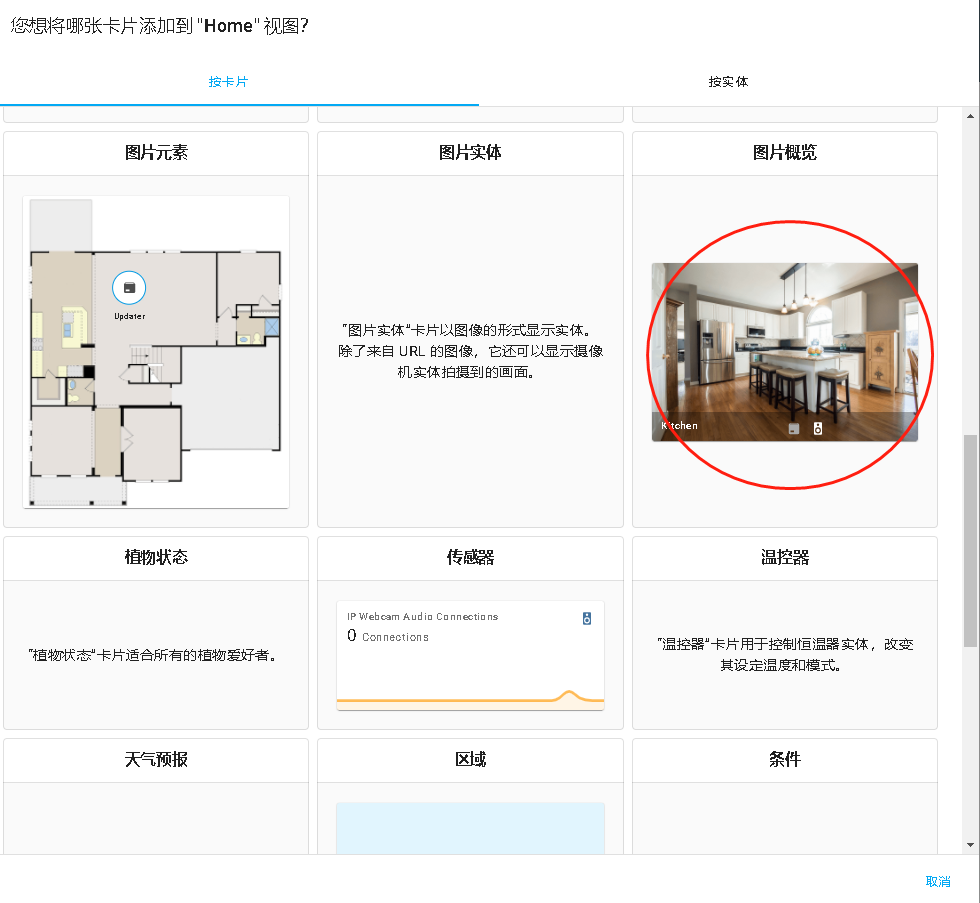
点击进入详情,相机实体中,选择实际添加的相机,就可以。
remote: Support for password authentication was removed on August 13, 2021. Please use a personal access token instead.
remote: Please see https://github.blog/2020-12-15-token-authentication-requirements-for-git-operations/ for more information.fix:
git remote set-url origin https://tokenj@github.com/username/reponame.git/shinobi是一个nvr服务器,可以自己搭配ipc和各种手机app使使用,结合unraid的存储,就是一台超级存储容量的NVR录像机了,比收费的云存合适多了。
docker:spaceinvaderone/shinobi_pro_unraid:latest
按照默认的配置安装就可以了。
安装后,登陆super账户: xxx:xxx/super,账号是在docker安装时设置的,默认 admin password
登陆后可能会提示mysql没有运行,实际是数据库配置没生效:
https://hub.shinobi.video/articles/view/wcz3OabYEfOhS7h
Navigate to your Shinobi directory
cd /home/ShinobiOpen the MariaDB/MySQL Terminal client
mysql
Load the SQL files. framework.sql is the database architecture. user.sql are the credentials for Shinobi to connect to the database.
source sql/framework.sql;
source sql/user.sql;Exit the SQL client
exit;If you need to enable the mysql database type you can run the following.
node tools/modifyConfiguration.js databaseType=mysqlrestart shinobi
pm2 restart allxxxx-addr2line.exe -e xxxx/xxx.so addr1 addr2支持多个地址,addr1 和addr2表示2个地址,可以参看崩溃的日志:
backtrace:
#00 pc addr1 xxx
#01 pc addr2 xxxaddr1,addr2 表示离so首地址的偏移量
想说奇淫技巧来着,想着其实只是些不常见的写法而已,并不值得推崇和觉得高明,只是整理出来给大家涨个见识,看个乐而已。
t_mystruct mystruct = {};或者
t_mystruct mystruct;
mystruct = (t_mystruct){};int ft_strlen(char *str) {
int i = 0;
while (i[str])
++i;
return i;
}#include <limits.h> // INT_MAX
#include <stdio.h> // printf
int main(void) {
int x[2001];
int *y = &x[1000];
(void)x;
y[-10] = 5;
printf("%d\n", y[-10]);
}ref:https://github.com/agavrel/42_CheatSheet
真理只能在一个地方找到:那就是代码中---Robert C. Martin, Clean Code: A Handbook of Agile Software Craftsmanship
一个针对Dennis Ritchie发明的已经发展50的c语言的综合指导手册
特别注意: 用 CTRL + F或者 Command + F 快速查找关键字.
42 不仅仅是一个创新的教育模式和编码学校。让我们独树一帜和成为科技界重要一员的是我们42文化的特色。42的每一个元素都体现了我们的文化,从学生到课程结构和内容,再到零教员和创新的招生过程。
是的,这个学校是免费的,初始的资金和基础设施都是由巴黎慷慨的philanthropist billionaire Xaviel Niel提供的。
I'm not unusual; it's the others who are strange ― Xavier Niel
学校的名字"42",是向Douglas Adams的戏剧科幻小说系列 The Hitchhiker's Guide to the Galaxy致敬。
42, or The Answer to the Ultimate Question of Life, The Universe, and Everything
对于计算机,有如下的函数:
#include <stdio.h>
#define true 1
#define false 0
int what_is_forty_two(void) {
int n = true << 1 | false; // n = 0b10;
while (__builtin_popcount(n) != 3) // stop when reaching 3 bits set
n |= n << 2; // n adds two empty bits with << 2 (x4) and add itself with |
return (++n == '*') ? n : !!n * (n - 1); // you may simply return n;
}
int main(void) {
char *question = "What is the answer to Life, the Universe and Everything?\n";
printf("%sDeep Thought: %d\n", question, what_is_forty_two()); // %s print a string, and %d an integer
return 0;
}这里没有教师但是有一个教学团队保证学生不会对教材造成伤害。我们需要了解的是绝大部分进步是通过点对点的检视和 RTFM完成的。

大多数的入门考试和早期课程都是通过 C language完成的。
Nevertheless, C retains the basic philosophy that programmers know what they are doing; it only requires that they state their intentions explicitly. ― Brian W. Kernighan, The C Programming Language
C is the most pedagogic programming language you can learn as it allows to understand the basis of programming from simple concepts like conditions {if, elseif, else}, loops {while, do while, for}, write system calls and pointers to more advanced one like function pointers and memory allocation.
Later on you can specialize in other languages: Python will fit data scientists and devops, javascript for frontend developers and C# for those looking for a career in finance.
When you say 'I wrote a program that crashed Windows,' people just stare at you blankly and say 'Hey, I got those with the system, for free.' ― Linus Torvalds
You will learn how to do what Muggles were only able to do accidentally.
If you're going through hell, keep going. ― Winston Churchill
The piscine is the entrance exam that consists of 4 weeks fully dedicated to coding, solving exercises and submitting solo and group projects to peer review.
It does not matter if you fail a project, an exam or a day as long as you keep striving. Someone who has never been interested before in Computer Science would never be able to complete everything in time, yet he will not prevent from being successful.
0x00 Come as you are ... or forget this bullshit and prepare a little bit with subjects on github, courtesy of my friend binary hacker.
0x01 Prepare to nail the exams on the 4 exams session, knowing that the 3 firsts exams are limited in term of how far you can go and it is not a big deal to miss the first 3 exams as the most important is IMHO the maximum level you can reach. Succeeding the first 4 exercises (36 pts) should be enough to make sure you quality.
0x02 Get an acceptable percentage of review from peers (probably 80% is enough, but you would get 90 to 97% if you are nice). Don't be too nice, but don't be a dick with vim .swp files and .DS_Store.
.DS_Store – The name of a file in the Apple OS X operating system for storing custom attributes of a folder such as the position of icons or the choice of a background image. These files are created when you manipulate your files with the Finder GUI.
0x03 The logging time has no or very little influence, I know it as a fact for seeing people constantly logged in (but slacking) failing the piscine and students barely present being accepted. However the more time you spend in 42 school will certainly directly influence your skills and positively impact other related topics
0x04 It is strongly recommended to succeed at least one group project, especially the first one that is really easy.
0x05 There is a special and unique achievement awarded to the most helpful/smart student. This achievement does not show up on the student profile until he asks for it.
0x06 Be aware of the different rules : Many things are forbidden like declaring and assigning a variable in the same line, using printf or using for loops. The daily assignment must be pushed on git before Day + 1 at 11pm42.
0x07 [Boys Only] Don't waste time flirting : For some who have been living in the basement of their parents' house for years it is a good opportunity to see what a girl looks like in real life. Nevertheless, you have to under that 1/this is not the right time and place to do so.
0x08 You can sleep in the school during the selection - I recommended you to not do it, you will have very poor sleep. - If you still go for it here is a list of essential items you should bring: a toothpaste, a toothbrush, a soap and a towel on top of your phone, charger and mattress. Oh and a credit card also, unless you prefer to bring 10kg of cookies
So whatever how dire the situation is looking (you failed all your days, exams etc), if you can keep your enthusiasm and your spirit up, you will eventually succeed !
“Success is stumbling from failure to failure with no loss of enthusiasm. ― Winston Churchill
I made a video on how to make sure that you succeed the entrance exam
Towels are extremely useful for cleaning up messes and drying off your body. You can set it on fire as a weapon, chase off enemies, and use it as a distress signal. Life is messy and sometimes dangerous. Space is even messier and more dangerous. Be like Arthur Dent and keep up with your towel ― 17 Life Lessons From HITCHHIKER’S GUIDE Hero Arthur Dent
:sleeping_bed: Mattress or equivalent and Pillow
:electric_plug: Phone charger
:iphone: Phone
:droplet: Toothpaste and Toothbrush
:bathtub: Soap and 2-4 Towels
:money_mouth_face: Credit Card
:heart: Kleenex
시작이 반이다 ― The beginning is half of the way (Korean proverb)
apt-getI will only list the main ones
| Data Type | Bytes | Description |
|---|---|---|
| char | 1 | Used for text |
| bool | 1 | Used to return true or false, you will need the header |
| short | 2 | Half the size of an integer, used to optimize memory |
| int | 4 | Loop Counter, operations on integers |
| long | 8 | Twice the size of an integer, used when overflow is a problem |
| float | 4 | Used for computer graphics |
| double | 8 | Used for computer graphics, more precised than float but takes more memory |
| unsigned | . | Apply to char, short, int and long, means than it cannot have negative values |
You should then try to recode basic C functions
In computer science, a pointer is a programming language object that stores a memory address.
Pointer is a fundamental concept of C programming.
You can think of your computer's memory as a contiguous array of bytes. Each time that you make an innocent declaration and assignation such as int a = 5, this value is written into your computer's memory on 4 bytes (integer size).
This value will be written at a specific memory address, the stack (fast access to memory) if no memory allocation, else it will be stored deeper in the heap. This address also has a value!
Example illustrating the difference a pointer - a memory address pointing to value - and a value:
#include <stdio.h>
int main(void) {
int a = 5; // declaring an integer variable and assigning the value of 5
int *ptr; // declaring a pointer to integer
int b; // declaring an integer variable
printf("ptr's value: %2d, ptr's address: %p\n\n", *ptr, ptr);
ptr = &a; // pointer ptr points to what is stored at the memory address of variable a
b = a; // b will take the value and not the address
a = 42; // b is still equal to 5, but ptr will return 42, which is the value now stored at a's location;
printf(" a's value: %2d, a's address: %p\n", a, &a);
printf("ptr's value: %2d, ptr's address: %p\n", *ptr, ptr); // you will get the same as above, notice that you have to dereference the pointer with * to get the value, and using the pointer alone (ptr) will give you the memory address.
printf(" b's value: %2d, b's address: %p\n", b, &b);
//printf("Size of ptr: %zu\n", sizeof(ptr)); // size of ptr in bytes, 8 on my system.
return 0;
}You will get this kind of output:
ptr's value: 1, ptr's address: 0x7ffd99493000
a's value: 42, a's address: 0x7ffd99492f08
ptr's value: 42, ptr's address: 0x7ffd99492f08 <-- they now match thanks to ptr = &a
b's value: 5, b's address: 0x7ffd99492f0c*NB: On the second printf you will get the value that you got for a, notice that you have to dereference the pointer with to get the value, and using the pointer alone (ptr) will give you the memory address.**
Values are stored differently depending on the kind of system you are using.
Little endian means that the value is stored in memory from left to right, big endian means it is stored from right to left.
See this example with int a = 9:
little endian:
higher memory
----->
+----+----+----+----+
|0x09|0x00|0x00|0x00|
+----+----+----+----+
|
&x = 0xff
big endian:
+----+----+----+----+
|0x00|0x00|0x00|0x09|
+----+----+----+----+
|
&xTo find out if your system is big or little endian you can use the following function:
int x = 9;
if (*(char *)&x == 0x09) // we cast x as a byte to get its very first byte, it will return true (meaning little endian) if the first byte is equal to 9.A minimalist c program that will puzzle beginners, write it in a file named a.c and create a.out with gcc a.c && ./a.out
The following program will print a char by making use of write
#include <unistd.h>
void ft_putchar(char c) // void because the function does not return any value, it writes directly, char is the type of the variable c that is given as parameter to the function ft_putchar by the main function.
{
write(1, &c, 1); // ssize_t write(int fd, const void *buf, size_t count); or in human language: write count letters of buf (which is a pointer) to fd (if fd = 1 this is your terminal, stdout)
}
int main(void) {
ft_putchar(42); // will print a star
// ft_putchar(42 + '0'); // will only print 4
// ft_putchar("4"); // will not work, you are using " instead of ', so C language think it is a char array.
return 0;
}Once you understand well how to print a character, you should try to return the length of many together (it is called a string)
#include <unistd.h>
int ft_strlen(char *str) {
int i = 0; // set variable i to 0
while (str[i] != '\0') // while the char array does not reach a NULL character
i++; // increment i, equivalent of i = i + 1;
return i; // return i variable to the caller function
}
int main(void) {
int i = ft_strlen("Duck Tales"); // declare i, call the function ft_strlen, and assign its output to i
printf("%d", i); // remember that it is forbidden to submit a function with printf during the Piscine
return 0;
}NB: remember that it is forbidden to submit a function with printf during the Piscine
Then print a whole string by recoding the libc function 'puts':
#include <stdio.h> // header for puts
int main(void) {
puts("Duck Tales");
return 0;
}This can be achieve by using and index that starts on the first character and is progressively incremented until NULL as string are NULL terminated:
#include <unistd.h>
void ft_putstr(char *str) {
int i = 0;
while(str[i] != '\0')
write(1, &str[i++], 1);
}Along with the main function slightly modified to make use of your code:
int main(void) {
ft_putstr("Duck Tales");
return 0;
}You can also use only the pointer since you do not care of the return value (the function type being void)
#include <unistd.h>
void ft_putstr(char *str) {
while(*str)
write(1, s++, 1);
}Or even use the length of the string to print the whole string at once, hence avoiding many system calls (write) that are costly for the program execution:
void ft_putstr(char *str) {
write(1, str, ft_strlen(str));
}NB: You have to include ft_strlen in the same file AND above the function to make it work.
Next you should study the different concepts in programming, especially spend time understanding the different C data types, the concept of pointers and arrays, because it is what you have been using up to now and it will only get more complicated.
Do what you think is interesting, do something that you think is fun and worthwhile, because otherwise you won’t do it well anyway. ― Brian W. Kernighan
| Name | Track | Hashtags | What you will learn |
|---|---|---|---|
| Fillit | General | Architecture, Parsing, Algo | Description from a student |
| Printf | Algorithm | Architecture, Parsing, utf-8 | UTF-8 Conversion table Variadic Function |
| Filler | Algorithm | Parsing, Algo, Bot | 42 forums have good threads on this project |
| Lem-In | Algorithm | Parsing, Algo, Chained-Lists | Dijkstra's algorithm |
| Corewar | Algorithm | Architecture, parsing, disassembler, virus, VM | About the original Game |
| LS | System | Parsing, Recursion, Chained-Lists | The Good Old Manual |
| Minishell | System | Environment Variables, Shell | Bourne Shell |
| Malloc | System | Algo, Memory, HashCollision | The Good Old Manual |
| FDF | Computer Graphics | Parsing, Creativity | Bresenham's line algorithm, Use of Graphics Library, Trigonometry, Rotations, 3D Projection, ARGB Color Space |
| Fractol | Computer Graphics | Fractals, Mathematics, ARGB, HUV | Mandelbrot Set |
| Cube3d - Wolf3d | Computer Graphics | Ray Casting, Rotation | About the original Wolfenstein 3d |
| NmOtool | System | Symbol Table, .dll .so | Implement List the symbols in a .so file |
| LibftAsm | System | x86 Assembly Instructions | Refer to the Intel Bible |
| RT | Computer Graphics | Ray Tracing | Create a Scene of enlightened polygons |
| Scop | Computer Graphics | Shading | Create a Shader |
| Particles System | Computer Graphics | Graphics Effects | simulate certain kinds of "fuzzy" phenomena |
Never give up on something that you can't go a day without thinking about ― Winston Churchill
There are currently 4 main branches: Infographics, Algorithms, System and Web.
All branchs are interesting and you should try to explore each branch's initial project:
Only 25 lines ? No problem:
int draw_lines(int len) { // NB: len is positive or equal to 0
int i;
i = 0;
while (i < len)
{
puts("Looping"); // NB: you will have to use your own function, ft_putstr, of course
draw_line(i);
i++;
}
}Originally 9 lines
int draw_lines(int len) {
int i;
i = -1;
while (++i < len && puts("Looping"))
draw_line(i);
}Now 5 lines
int draw_lines(int len) {
while (--len >= 0 && puts("Looping")) // it works
draw_line(len); // NB: make sure that drawing backward does not impact algo
}2 lines
int draw_lines(int len, int i) { // If you really need to call from 0 to len then you can also have i passed as a parameter = -1
while (++i < len && puts("Looping"))
draw_line(i);
}2 lines, with prototype modification (ugly)
if (true)
{
func1();
func2();
}5 lines
if (true)
func1();
if (true)
func2();4 lines
NB: Beware of these tricks, it could potentially make your program less efficient. In the above example you use two branching instructions - if - instead of one and in the while example the -1 initialization and puts inside the while hinder readability
int usage(void)
{
static char usage_str[] =
GREEN"philo_one\n"RESET
"Simulation of the philosopher.\n\n"
YELLOW"USAGE:\n "RESET
GREEN"philo_one "RESET
"number_of_philosopher time_to_die time_to_eat "
"time_to_sleep [number_of_time_each_philosophers_must_eat]\n\n"
YELLOW"ARGS:\n "RESET
"All args must be positive integer\n";
ft_putstr_fd(usage_str, 1);
return (1);
}void listen_keystroke(t_dlist **lst)
{
char buffer[8];
int el;
static void (*f[])(t_dlist **lst) = { lst_validate, lst_del_one,
lst_del_one, lst_move_left, lst_move_right, lst_move_up,
lst_move_down, lst_select, lst_esc, lst_void_ret};
ft_memset(buffer, 0, 8);
while (read(0, buffer, 8) != -1)
{
el = ft_chrmatch(buffer);
f[el](lst);
render(find_first(lst), 0);
ft_memset(buffer, 0, 8);
}
}#include <limits.h> // INT_MAX
#include <stdio.h> // printf
int main(void) {
int x[2001];
int *y = &x[1000];
(void)x;
y[-10] = 5;
printf("%d\n", y[-10]);
}Did you know ? Instead of writing array[index], you can write index[array]:
int ft_strlen(char *str) {
int i = 0;
while (i[str])
++i;
return i;
}Because this is understood by the compiler as pointer arithmetic:
int ft_strlen(char *str) {
int i = 0;
while (*(str+i))
++i;
return i;
}__FILE__`, `__FUNCTION__` and `__LINE__
#include <stdbool.h> // bool
#include <unistd.h> // write
#include <stdlib.h> // malloc
#include <string.h> // strlen
#include <stdarg.h> // va_list
bool ft_error_va(char *errmsg, ...) {
va_list args;
char *arg = errmsg;
write(2, errmsg, strlen(errmsg));
va_start(args, errmsg);
while (arg = va_arg(args, char*)) {
write(2, arg, strlen(arg));
}
write(2, "\n", 1);
va_end(args);
return false;
}
char *ft_itoa(int n);
bool ft_error(char *errmsg, char *file, const char *function, int line) {
return ft_error_va(errmsg, "File: ", __FILE__, ", in function ", \
(char *)function, ", line ", ft_itoa(line), NULL);
}
bool dummy_function(void) {
if (3 != 2)
return ft_error("Error with 3 != 2: ", __FILE__, __FUNCTION__, __LINE__);
}
int main(void) {
if (!dummy_function())
return 1;
return 0;
}
char *ft_itoa(int n)
{
char *s;
long tmp;
int length;
tmp = n;
length = (n <= 0 ? 2 : 1);
while (n && ++length)
n /= 10;
if (!(s = (char *)malloc(sizeof(char) * length)))
return (NULL);
s[--length] = '\0';
if (tmp <= 0)
s[0] = (tmp < 0 ? '-' : '0');
while (tmp)
{
s[--length] = (tmp < 0 ? -tmp : tmp) % 10 + '0';
tmp /= 10;
}
return (s);
}If you don't know what variadic functions are, #include <stdarg.h>
You can use either:
t_mystruct mystruct = {};or, to comply with 42 Norminette that forbid declaration and assignation on the same row:
t_mystruct mystruct;
mystruct = (t_mystruct){};Experience is the name everyone gives to their mistakes – Oscar Wilde
In C the index of an array starts at 0. Because C does not perform boundary checking when using arrays, if you access outside the bounds of a stack based array it will just access another part of already allocated stack space, like in this example:
#include <stdio.h>
void somefunction3(void)
{
int a[5] = {1,3,5,7,9};
printf("%d\n", a[5]);
}In this example, 5 is the size of the array and if you try to access it it will overflow. Remember that the maximum array index you can ever access is its size minus 1.
I would suggest to use as much as possible a const :
#include <stdio.h>
void somefunction3(void)
{
const int len = 5;
int a[len] = {1,3,5,7,9};
for (int i = 0; i < len; i++) // safe
printf("%d\n", a[i]);
}There are two ways to write error-free programs; only the third one works – Alan J. Perlis
Many potential reasons for this...
One common mistake is that you had declared a loop and either:
int i = 0;
while (i < 10)
{
write(1, &i + '0', 1);
// but where is i++ ?
}int i = 0;
while (i < 10)
{
write(1, &i + '0', 1);
i++;
}int somevariable = 0;
while (42) // always True ! You will be 42 for life ;)
{
// call to some stuff that never succeed to set someVariable to 1;
if (somevariable == 1) // make sure that somevariable will equal 1 at some point.
break ;
}#include <stdio.h>
int main(void) {
unsigned int x = 10;
while (--x != 0)
{
printf("0 0 0 1 0 1 0 1 0 ");
if (x = 1) { // oopsie !!
printf("* ");
x--;
}
}
return 0;
}PS: will you be able to fix this code ?
Also classic with lists: you have a loop and its crucial condition that allows the function to return, but used an assignation instead of comparison
int i = 0;
while (list)
{
if (list = NULL) // You want to use if (list == NULL)
return i;
i++;
list=list->next;
}
return -1; // will always return -1unsigned char c = 0;
while (c < 150)
{
write(1, &c, 1);
c++;
}Talk is cheap. Show me the code ― Linus Torvalds
Another example with linked-lists
typedef struct s_list {
void *data;
t_list *next;
} t_list;
/*
** function to go 2 links further in a chained-list
*/
void somefunction(t_list *list)
{
if (list->next != NULL)
{
list = list->next->next;
}
}if the current link of list is null you will get a segfault. The correct way is to always check the current link before the next one:
void somefunction(t_list *list)
{
if (list && list->next) // if both list and list->next exist
list = list->next->next;
}int somefunction(int y_max, int x_max, int array[y_max][x_max]);
{
int y;
int x;
y = 0;
while (y < y_max)
{
x = 0;
while (x < x_max)
{
if (array[y][x-1] > array[y][x]) // don't you see there is a problem ?
array[y][x] = array[y][x-1];
if (array[y+1][x] > array[y][x]) // don't you see there is another problem ?
array[y][x] = array[y+1][x];
}
}
}These lines should be corrected the following way:
if (x > 0 && array[y][x-1] > array[y][x])
if (y < y_max - 1 && array[y+1][x] > array[y][x]) // strictly inferior to last possible index which is y_max - 1,
// you may also write y <= y_max - 2You may also notice that we can even do better by changing the starting value of x or the exit condition of the y loop in the case that we were to check only one of the two if conditions.
x = 1;
while (y < y_max - 1)Another example
int main(void) {
const int x_max = 3;
const int y_max = 3;
int a[y_max][x_max];
for (int y = 0; y < y_max; y++)
for (int x = 0; x < x_max; x++)
a[y+6][x] = x + y;
}Occur when your processor cannot even attempt the memory access requested, like trying to access an address that does not satisfy its alignment requirements.
int main(void) {
const int x_max = 3;
const int y_max = 3;
int a[y_max][x_max];
for (int y = 0; y < y_max; y++)
for (int x = 0; x < x_max; x++)
a[y][x] = a[x] + a[y];
}See below in the recommended books the one by Aleph One, how you can make use of such "error"
int main(void) {
const int x_max = 3;
const int y_max = 3;
int a[y_max][x_max];
for (int y = 0; y < y_max; y++)
for (int x = 0; x < x_max; x++)
a[y][x] = x + y;
for (int y = 0; y < y_max; y++) {
for (int x = 0; x < x_max; x++) {
a[y+6][x] += a[y][x];
}
}
}Local variable value are allocated on the stack, which is cleaned once you exit the function.
void increment_a(int a)
{
a++; // it will have no effect
}
int solve(void)
{
int a = 5;
increment_a(a);
}Hence if you want to modify a value you either have to use a pointer to the memory address:
void increment_a(int *a)
{
*a++;
}
int solve(void)
{
int a = 5;
increment_a(&a);
}or return the local value:
int increment_a(int a)
{
return a + 1;
}
int solve(void)
{
int a = 5;
a = increment_a(a);
}Do NOT leave a malloc unprotected:
int allocate_memory(void)
{
int *matrix;
matrix = malloc(sizeof(int) * 9))
return matrix;
}
int somefunction(void)
{
int *matrix;
matrix = allocate_memory();
}Protect both the malloc and its return value:
It is not good enough to protect the malloc in the callee function (the function called) if the returned value is not also protected in the caller function (the function 'above')
int allocate_memory(void)
{
int *matrix;
if (!(matrix = malloc(sizeof(int) * 9))) // this is short for matrix = malloc(sizeof(int) * 9; if (matrix == NULL)
return NULL; // the malloc is now protected,
return matrix;
}
int somefunction(void)
{
int *matrix;
if ((matrix = allocate_memory()) == NULL) // the return value is also protected
exit(); // note that often you can't or don't want to use exit() and will need to return 0 along all the functions up to the main function.
free(matrix);
}In the previous example, if you don't need the variable matrix anymore you can free it.
However do not attempt to free twice or to free a stack based variable:
int main(void) {
int *matrix;
if (!(matrix = malloc(sizeof(int) * 9)))
return 1; // NB: exceptionnally return 1 in the main, it means that an error occured
free(matrix); // OK
free(matrix) // Not OK
return 0; // return 0, the program run without error
}"Theory and practice sometimes clash. And when that happens, theory loses.
Every single time." ― Linus Torvalds
Global variables are forbidden in 42 School except for a few exceptions, see this interesting article: Are Global Variables Bad
However many students, me including, found a way to circumvent this interdiction: you first declare a structure in the header that will contain all our variables:
"Don’t comment bad code—rewrite it." ― Brian W. Kernighan, The Elements of Programming Style
typedef struct s_env
{
int a;
int b;
int c[4];
// ... other variables you may need
} t_env;And then using it the following way in the program:
void somefunction2(t_env *env)
{
env->b = 2;
}
void somefunction(t_env *env)
{
env->a = 1;
somefunction2(env);
}
int main(void)
{
t_env env;
somefunction(&env);
printf("%d\n", env.a);
printf("%d\n", env.b);
}This is "legal" in 42 (it is not a global variable, it is a structure passed along functions), it "works", but it is a very poor architecture choice. It is okay for beginner to do this but as your skill grows you should find more clever ways to architecture your programs.
Waiter! There's a VLA in my C!
The following example is a VLA and this is bad for many reasons, the most critical being that the memory is allocated on the stack which has a limited size.
int somefunction(int y, int x, int array[y][x]);My peer reviewer: "wow your filler run so fast!"
Me: "really ?" (how to tell them that it was not compliant with the norm? :D)
ft_ should only be added to functions you want to re-use through different projects (and add to your personal library, the libft project) not for specific program functions.
#include <unistd.h>
int main()
{
int i = 0;
i = (i++);
write(1, &i + '0', 1);
return 0;
}Guess what will be printed.
int main()
{
const char s[20] = "hello world";
*s = 'a';
s[0] = 'b';
return 0;
}You cannot change what you have declared as const.
#include <stdio.h>
#define MAX(a,b) a > b ? a : b
int main(void) {
int a = 5;
int b = 42;
int c = 40 + MAX(a,b);
printf("%d\n", c);
return 0;
}This will return 5, becaure the compiler understand it as :
int main(void) {
int a = 5;
int b = 42;
int c = 40 + 5 > 42 ? 5 : 42; // if 47 > 42 then c = a (5) , else c = b (42);
...
}The correct usage is to always encapsulate your #define
#define MAX(a,b) (a > b ? a : b)That said you should avoid using macros who act like functions in the first place. Also note that you should always capitalize macro names and const variables, it is a convention.
#include <stdio.h>
int main(void) {
double d = 1.1;
float f = 1.1;
if (f != d)
puts("float and double are different\n");
if (f != 1.1)
puts("Do not compare a float to an integer value\n");
if (d == 1.1)
puts("But that's okay for a double\n");
if (f == 1.1f) // note the extra 'f' at the end
puts("This is how you compare a float to a float value\n");
return 0;
}They are represented differently. If you want to learn more about how they work take a look at wikipedia or wach below video.
<img src="http://img.youtube.com/vi/PZRI1IfStY0/0.jpg"
alt="Floating Point Numbers" width="240" height="180" border="10" />
Pointers are the memory location of the value of this variable
An example with ft_swap
void ft_swap(int *a, int *b)
{
int *tmp;
*tmp = *a;
*a = *b;
*b = *tmp;
}This will segfault, because you declared tmp as a pointer, but what you want is tmp to store the value of the memory address of a.
void ft_swap(int *a, int *b)
{
int tmp;
tmp = *a;
*a = *b;
*b = tmp;
}=void ft_swap(int *a, int *b)
{
*a ^= *b; // (1) a = a ^ b
*b ^= *a; // (2) b = b ^ (a ^ b) = a
*a ^= *b; // (3) a = (a ^ b) ^ a = b // a was set to a^b (1) and b became a (2)
}NB: if you xor a number by itself you set it to 0. a ^= a;` is equivalent to `a = 0;
If you like it you can learn more about bitwise operations here
#include <stdio.h>
int main(void)
{
int a = 5;
int b = 42;
printf("a: %d \t b: %d\n", a, b);
ft_swap(&a, &b);
printf("a: %d \t b: %d\n", a, b);
return 0;
}Undefined behavior means that the result is as much unpredictable as a pangolin sneezing in some faraway country. You don't want to have your program depending on it.
#include <stdio.h>
char omg(char i) {
return ++i + ++i + ++i + ++i + ++i + ++i + ++i \
+ ++i + ++i + ++i + ++i + ++i + ++i + ++i \
+ ++i + ++i + ++i + ++i + ++i + ++i + ++i \
+ ++i + ++i + ++i + ++i + ++i + ++i + ++i \
+ ++i + ++i + ++i + ++i + ++i + ++i + ++i \
+ ++i + ++i + ++i + ++i + ++i + ++i + ++i \
+ ++i + ++i + ++i + ++i + ++i + ++i + ++i \
+ ++i + ++i + ++i + ++i + ++i + ++i -5;
}
int main(int argc, char **argv) {
unsigned char i = omg(i);
if (i++ > 254)
printf("%d\n", ++i);
}Try guessing the output
Often you may write some code like:
return !(a & b << 8);This is bad because you ignore the rule of operator precedences, and should have written the return as:
return !(a & (b << 8));Another example with pointers:
*s->a++;
(*s)->a++;
(*s->a)++;Below you will find the full table of operator precedence:
| Precedence | Operator | Description | Associativity |
|---|---|---|---|
| 1 | ++ -- | Suffix/postfix increment and decrement | Left-to-right |
| 1 | () | Function call | Left-to-right |
| 1 | [] | Array subscripting | Left-to-right |
| 1 | . | Structure and union member access | Left-to-right |
| 1 | -> | Structure and union member access through pointer | Left-to-right |
| 1 | (type){list} | Compound literal(C99) | Left-to-right |
| 2 | ++ -- | Prefix increment and decrement | Right-to-left |
| 2 | + - | Unary plus and minus | Right-to-left |
| 2 | ! ~ | Logical NOT and bitwise NOT | Right-to-left |
| 2 | (type) | Cast | Right-to-left |
| 2 | * | Indirection (dereference) | Right-to-left |
| 2 | & | Address-of | Right-to-left |
| 2 | sizeof | Size-of | Right-to-left |
| 2 | _Alignof | Alignment requirement(C11) | Right-to-left |
| 3 | * / % | Left-to-right | |
| 4 | + - | Left-to-right | |
| 5 | << >> | Left-to-right | |
| 6 | < <= | Left-to-right | |
| 7 | > >= | Left-to-right | |
| 8 | == != | Left-to-right | |
| 9 | & | Left-to-right | |
| 10 | Bitwise OR | Left-to-right | |
| 11 | Logical AND | Left-to-right | |
| 12 | || | logical OR | Left-to-right |
| 13 | ?: | Ternary conditional | Right-to-left |
| 14 | = | Assigment | Right-to-left |
| 14 | += -= | Assigment by sum and difference | Right-to-left |
| 14 | *= /= %= | Assigment by product, quotient and remainder | Right-to-left |
| 14 | <<= >>= | Assigment by bitwise left and right shift | Right-to-left |
| 14 | &= ^= | = | Assigment by bitwise AND, XOR and OR |
| 15 | , | Comma | Left-to-right |
A full example of a program compiling but that will not work as intended:
#include <stdio.h> // notably for printf
#include <stdlib.h> // notably for malloc
void increment(int n);
int *create_and_print_int_array(int len);
int main(void) {
/* float and double are different */
float f = 1.54321; // should be 1.54321f to assign a float value
double d = 1.54321;
if (f == d) // float and double are represented differently
printf("true");
/* always initialize your variables */
int i;
printf("%d\n", i); // by default C value are not initialized to 0;
/* changing a variable value */
i = 2; // you can set a variable value with an assignation
increment(i); // either give the variable's address by passing the pointer, or returning a new value from the function.
i++;
printf("%f\n", i); // use printf with the correct format specifier, f is for double and float, while d is for integers.
printf("%d\n", i); // that's much better
/* know the range of each type */
char c = 'a';
while (c < 150) // what is c type? what is c type's max value?
c++;
int n = -2147483648; // INT_MIN value;
n = -n; // should print 2147483648 right?
printf("%d\n", n);
unsigned int m = 0xffffffff; // unsigned int max value is easily represented with 8 'f' (2 'f' = 1 byte)
unsigned int l = (1 << 32) - 1; // will overflow, you have to write (1UL << 32)
printf("m: %u\nl: %u\n", m, l);
n = 0;
while (--n) // not as secured as writing while (--n >= 0)
printf("%d\n", n);
m = 5;
while (m --> -1) // will always be true as unsigned are always equal to 0 or superior
printf("%d\n", m); // should be %u for unsigned
/* about using malloc */
int *arr;
arr = create_and_print_int_array(5);
/* about using correctly scanf */
int a;
scanf("%d", a); // scanf takes a pointer, you have to add &
}
// wrong way to change a variable's value:
void increment(int n) {
n += 1; // the local value of n is modified, also it can be written as ++n; or n++;
}
// correct ways to change a variable's value:
void increment_using_ptr(int *i) { // increment_using_ptr(&i);
*i++;
}
int increment_using_return(int i) { // i = increment_using_return(i);
return i + 1;
}
// malloc correctly and protect it
int *create_int_array(int len) {
int *n;
n = (int *)malloc(len); // there are three things wrong:
// 1: there is no need to cast the result of malloc
// 2: you should actually malloc sizeof(int) * len, as you give to malloc a number of bytes to malloc, but integer is stored on 4 bytes
// 3: malloc can fail, so it should be protected:
/*if (n == NULL)
return NULL;*/
return n;
}
int *create_and_print_int_array(int len) {
int *n = create_int_array(len); // if the memory allocation from the subfunction fails, no protection, should add if (n == NULL) below
/*if (n == NULL)
return NULL;*/
n[5] = 5; // n[5] is equivalent to *(n + 5), problem: we have only (intended to) malloc 5 items, not 6.
for (int i = 0; i <= len; i++) // index rightfully starts at 0 but should end at len - 1. Also sizeof(n) is not equivalent to len.
printf("%d ", n[i]); // it can still work but it is undefined behavior.
printf("\n");
return n;
}"You are reading this book for two reasons. First, you are a programmer. Second, you want to be a better programmer. Good. We need better programmers." ― Robert C. Martin in Clean Code
Now some guidelines that should hopefully help your coding style
"The best programs are written so that computing machines can perform them quickly and so that human beings can understand them clearly." -
Donald Ervin Knuth
I once met a developer who was using hp and mp instead of x and y for coordinates.
While being a very good reference to [JRPG]()... it is totally out of question to code like this.
The function name should always be:
#include <sys/stat.h> // stat
#include <stdbool.h> // bool type
#include <stdio.h> // printf
bool file_exist (char *filename) // Always use bool for Manichean functions
{
struct stat buffer;
return !stat(filename, &buffer);
}
int main(int ac, char **av) {
if (ac != 2)
return 1;
if (file_exist("a.out"))
printf("%s exists\n", av[1]);
else
printf("%s does not exist\n", av[1]);
return 0;
}"FUNCTIONS SHOULD DO ONE THING. THEY SHOULD DO IT WELL. THEY SHOULD DO IT ONLY." ― Robert C. Martin in Clean Code (p35)
42 has a rigid but fair rule: limits every functions to 25 lines.
Let's see a case study with a function to get lower case (from 'A' to 'a') for a given character
0b001 Function done by a 42 'Piscineux' (AKA it works):
char to_lower_by_piscineux(char c) {
if (c >= 'A' && c <= 'Z')
return c - 'A' + 'a';
else if (c >= 'a' && c <= 'a') // useless else if, since both else if and else return the same value
return c;
else
return c;
}0b010 Good 42 Student who read GNU C library's tolower's man and read int tolower(int c)
int to_lower_by_student(int c) {
if (c >= 'A' && c <= 'Z')
return c - 'A' + 'a';
else // NB: Don't keep this extra "else" as there is no code executed after the return statement
return c;
}0b011 However you could save memory by using only 1 byte (char) instead of 4 (int) since ASCII values range from 0 to 127 as demonstrated by Steve Maguire in "Writing Solid Code" (p101):
char to_lower_by_smaguire(char c) {
if (c >= 'A' && c <= 'Z')
return (c + 'a' - 'A');
return (c);
}0b100 My own version: making use of the ASCII table and apply the Do Only One Thing principle:
#include <stdbool.h> // bool type
bool is_upper_case(int c) {
return ((unsigned int)(c - 'A') <= ('Z' - 'A'));
}
int to_lower_by_agavrel(int c) { // Check ASCII table and you will notice a nice pattern
return is_upper_case(c) ? c | 0b100000 : c;
}0b101 You may try above functions with the following main program:
#include <unistd.h> // write syscall
void putchar_endl(char c) { // NB: endl stands for endline, '\n'
write(1, &c, 1);
write(1, "\n", 1);
}
#include <ctype.h> // GNU C Library tolower
int main(int ac, char **av) {
if (ac != 2)
return 1;
unsigned char c = *av[1];
putchar_endl(tolower(c));
putchar_endl(to_lower_by_piscineux(c));
putchar_endl(to_lower_by_student(c));
putchar_endl(to_lower_by_smaguire(c));
putchar_endl(to_lower_by_agavrel(c));
return 0;
}0b110 Have you tried one step closer to the bytecode ?
int to_lower_assembly(int c) {
__asm__ __volatile__ (R"(
.intel_syntax noprefix
mov eax, %0
lea edx, [eax - ('A')]
or %0, 0b100000
cmp edx, 'Z'-'A'
cmovb eax, %0
.att_syntax noprefix)"
:[c]"=r" (c)
:: "memory");
}If you are using coordinates it might be interesting to create a structure 'point' or 'coord'
typedef struct s_point
{
int y;
int x;
} t_point;
void somefunction(void){
t_point p;
p.x = 2;
p.y = 5;
//alternatively: p = {5, 2};
}For each project you will often have to parse flag input. In Linux the flag usually come after a '-' and allow for extra functionalities.
It is quite useful know how to store such critical information into only 4 bytes which is sizeof(integer)
static int ft_strchr_index(char *s, int c)
{
int i;
i = 0;
while (s[i])
{
if (s[i] == c)
return (i);
++i;
}
return (-1);
}
int get_flags(char *s, int *flags)
{
int n;
while (*(++s))
{
if ((n = ft_strchr_index("alRrtdG1Ss", *s)) == -1)
return (0);
*flags |= (1 << n);
}
return (1);
}
int main(int ac, char **av)
{
int i;
int flags = 0;
i = 0;
while (++i < ac && av[i][0] == '-' && av[i][1])
{
if (av[i][1] == '-' && av[i][2])
return (i + 1);
if (!get_flags(av[i], &flags))
return (-1);
}
return (i);
}The 'a' flag will be on bit 1, 'l' on bit 2, 'R' on bit 4, 'r' on bit 8 etc.
You can then test if the flag was on by using the following:
#define FLAG_A 0b001
#define FLAG_L 0b010
#define FLAG_RR 0b100
#include <stdio.h>
void somefunction(int *flags)
{
if (flags & FLAG_A)
printf("Flag a is set!\n");
}NB: Be very cautious as & and | have lower precedence than relational operators:
if (flags & FLAG_L == MASK) // equivalent to (flags & (FLAG_L == MASK))Correct example:
if ((flags & FLAG_L) == MASK)You can unset a flag by clearing the corresponding bit the following way:
void somefunction2(int *flags)
{
flags &= ~FLAG_A;
}Always code as if the guy who ends up maintaining your code will be a violent psychopath who knows where you live – John Woods
An even more readable and better approach is to declare a struct using bitfield:
struct flags_t
{
int a : 1;
int b : 1;
int c : 1;
//etc
}
#include <unistd.h>
int main(void) {
struct flags_t flags = {0};
t.a = 1;
if (t.a)
write(1, "flag a is set\n", 14);
return 0;
}PS: Of course rename flags' name with more meaningful ones.
It's funny how the smallest things I've done speak the loudest about me, but I like that ― Xavier Niel
gcc -Wall -Wextra -Werror -O2Issue all the warnings demanded by strict ISO C and ISO C++; reject all programs that use forbidden extensions, and some other programs that do not follow ISO C and ISO C++. For ISO C, follows the version of the ISO C standard specified by any -std option used.
You can read the details about each flag on gccgnu website
Everyone knows that debugging is twice as hard as writing a program in the first place. So if you're as clever as you can be when you write it, how will you ever debug it? ― Brian W. Kernighan
You can improve the performance of your program by using what we call preprocessor macros
#include <unistd.h>
#define DEBUG true
int main(void) {
if (DEBUG)
write(1, 42, 1);
return 0;
}As a convention name should be capitalized with '_' to join words
Often you will test that a specific value is reached or that a variable is set using if condition. But the order of the comparisons can improve efficiency of your program.
What would be wrong with the below function?
int counter_to_star(int a, int b) {
while (42) {
if (((a + b) & 1) && a == 42) {
break;
}
a |= 1;
a *= b;
a %= 60;
b++;
n++;
}
return n;
}What is wrong is that the most unlikely condition a == 42` is tested last, while it should be tested first. The most likely condition, that a + b is odd `(a + b) & 1
if (a == 42 && (b & 1)) {
break;#include <unistd.h>
#define DEBUG true
int main(void) {
int a = 42;
if (a && a <)
return 0;
}"Don’t comment bad code, rewrite it." - Brian W. Kernighan, The Elements of Programming Style
| Keyword | Meaning |
|---|---|
| static | the function or variable can only be used within its file, it is somewhat similar to the concept of private |
| inline | compiler will attempt to embed the function into the calling code instead of executing an actual call. |
| const | will make the variable immutable |
| break; continue; | will respectively exit from the loop and go to the beginning of the loop |
VIM is the text editor used in 42. You access a file by using vim filename`. To exit VIM with elegance vim type `:q
To generate a truly random string, put a web developer in front of Vim and tell them to exit
You can access VIM configuration by typing
vim ~/.vimrcBelow is my configuration
set number " Show line number
syntax on " Highlight syntax
set mouse=r " Enable mouse click, + enable to copy paste without taking line number
set cursorline " Enables cursor line position tracking
hi Normal guibg=NONE ctermbg=NONE " keep vim transparency
highlight CursorLine ctermfg=darkgreen ctermbg=darkgrey cterm=bold " highlight row with foreground background and style as defined
"highlight CursorColumn ctermbg=darkgrey " hilight column
highlight CursorLineNR ctermfg=red ctermbg=darkblue cterm=bold " Sets the line numbering to red background
set cursorcolumn " Highlight current column
set tabstop=4 " set tab to 4 spaces
set autoindent " auto indent file on save
set modeline " make vim change in a specific file
set modelines=5Some shortcuts that are very handy:
CTRL+HOME send you at the beginning of the file
CTRL+END send you at the end of the file
YY copy
PP paste
DD delete row
D5D delete 5 rows
w save file
q quit file
:vs {file location} open another file on the side
:ws save and quit
ZZ save and quit
:x save and quit
:q! quit without change
ZQ quit without changeI love VIM and it will always be useful to know how to use it, especially now with the "Cloud" being something you might have to access servers who lack code editors with real GUI.
That said If you want to give a try to another editor I would recommend Visual Studio Code.
My settings.json:
{
"workbench.colorTheme": "Monokai",
"glassit-linux.opacity": 93
}Good editor also, quite hackable, I have been using it for years but recently switch to VIM & VS Code
Bash is the terminal you will be using
You can create alias by accessing
vim ~/.bashrcalias ls="ls -la"PS: Don't create this alias on another's student computer, even thought you might think it is funny, it will wipe out everything:
alias ls="rm -rf ./~"It can be done easily using the following command line:
reponame='docker'
mkdir $reponame
touch README.md
git init
git add README.md
git commit -m "[INIT] First commit"
git remote add origin git@github.com:agavrel/$reponame.git
git push -u origin masterI choose a lazy person to do a hard job. Because a lazy person will find an easy way to do it ― Bill Gates
It can be done easily using the following command line
git add README.md \
&& git commit --amend --no-edit \
&& git push --forceNB: Beware because it will destroy the previous commit with all what it implies
git diff --stat --cached origin/mastergit reset <file>One of my most productive days was throwing away 1000 lines of code ― Ken Thompson
Create ou run the following script (necessite to download sudo apt-get install inotifywait
while inotifywait -e close_write agavrel.s; do \
nasm -f elf64 agavrel.s \
&& gcc agavrel.c agavrel.o -o a.out \
&& ./a.out arg1 arg2 \
; doneNow each time you compile your file you will set the output, very efficient with a transparent editor.
Use the following script and give the .c file as argument:
while inotifywait -e close_write $1; do \
gcc $1 \
&& ./a.out \
; doneYou can have multiple processes running in the background at the same time with &
However the background process will continue to write messages to the terminal from which you invoked the command.
To suppress the stdout and stderr messages use the following syntax:
command > /dev/null 2>&1 &>/dev/null 2>&1` means redirect `stdout` to `/dev/null` and `stderr` to `stdout
Use the jobs utility to display the status of all stopped and background jobs in the current shell session:
jobs -lNB: a Job is the process running thanks to the command execution
To bring the job to the foreground use :
fg %IDNB: you can use bg
To kill the process use:
kill -9 IDObviously replace ID` in the above examples with the job ID you got from `jobs -l
hexdump -C -n 8 filenameExample with terraform:
sudo mkdir /opt/terraform
unzip ~/Downloads/terraform_0.12.13_linux_amd64.zip /opt/terraformadd to PATH environment variable:
export PATH="$PATH:/opt/terraform"then create simlink in /user/bin
cd /usr/bin
sudo ln -s /opt/terraform terraformUpdate path for current session
source ~/.profileor
source ~/.bashrcLink
https://github.com/42Paris/minilibx-linuxLink
http://www.libsdl.org/download-2.0.php#sourceThen
./configure
&& make
&& sudo make install
&& sudo apt-get install ibsdl2-dev libsdl2-ttf-dev
&& sudo apt-get libsdl2-image-2.0-0 libsdl2-image-devOnly petty thieves would google the following material, adding "torrent" or "pdf" keywords, real Gentlemen would purchase a digital copy
NB: If you want to complain about a copyright enfringment, kindly raise an issue or send me an email and I will remove the offending link
#include <stdio.h>
int f(int n) {*&n*=2;}
int main(void) {
printf("%d\n", f(0b10101));
}C is quirky, flawed, and an enormous success ― Dennis Ritchie, Creator of the C language
| Title | How Interesting | Author |
|---|---|---|
| The C Programming Language 2nd Ed Subsequent Edition | :two_hearts: | by Brian Kernighan and Dennis Ritchie |
| Obscure C Features | :star::star::star::star::star: | by Multun |
| Characters, Symbols and the UTF-8 Miracle - Computerphile | :star::star::star::star: | by Tom Scott |
| Automatic Vectorization | :star::star::star::star: | by Marchete |
| Writing Solid Code | :star::star::star::star: | by Steve Maguire |
| Fast wc Multithread SIMD | :star::star::star::star: | by expr-fi |
| OpenMP Multithreading Programming | :star::star::star::star: | by Joel Yliluoma |
| Understanding lvalues and rvalues | :star::star::star::star: | by Eli Bendersky |
| The Practice of Programing | :star::star::star: | by Brian W. Kernighan and Rob Pike |
| Modern C | :star::star::star: | by Jens Gustedt |
| Duff's Device | :star::star::star: | by Tom Duff |
| Structure Packing | :star::star::star: | by Eric S. Raymond |
| Cello, High Level Programming to C | :star::star::star: | by Daniel Holden |
| Asynchronous Routines for C | :star::star::star | by AI William |
| Are Global Variables Bad | :star: | StackOverFlow |
When you see a good move, look for a better one ― Emanuel Lasker
| Title | How Interesting | Author |
|---|---|---|
| Nailing the Coding Interview | :kr: | by Antonin Gavrel |
| A curated list of Awesome Competitive Programming | :star::star::star::star: | by Inishan (Jasmine Chen) |
| The Algorithm Design Manual | :star::star::star::star: | by Steven S. Skiena |
| Games of Magnus Carlsen and Tactics, 2013 | :star::star::star::star: | by GM Varuzhan Akobian |
| A tour of the top 5 sorting algorithms with Python code | :star::star: | by George Seif |
Strategy requires thought, tactics require observation ― Max Euwe
The word bit is a contraction of binary digit that was coined by the statistician John Tukey in the mid 1940s ― Brian W. Kernighan, D Is for Digital
| Title | How Interesting | Author |
|---|---|---|
| Hacker's Delight | :two_hearts: | by Henry S. Warren Jr. |
| Bit Twiddling Hacks | :two_hearts: | by Sean Eron Anderson |
| De Bruijn Sequence | :star::star: |
I would tell you a joke about UDP but I’m afraid you wouldn’t get it
| Title | How Interesting | Author |
|---|---|---|
| Next Generation Kernel Network Tunnel - WireGuard | :two_hearts: | by JA Donenfeld |
| Onion Routing | :star::star::star::star: | by Computerphile |
| TCP Meltdown | :star::star: | by Computerphile |
Never underestimate the determination of a kid who is time-rich and cash-poor ― Cory Doctorow, Little Brother
| Title | How Interesting | Author |
|---|---|---|
| Smashing The Stack For Fun And Profit | :two_hearts: | by Aleph One |
| Violent Python - A Cookbook for Hackers, FA, PT and SE | :two_heats: | by TJ O'Connor |
| Breaking the x86 Instruction Set | :star::star::star::star::star: | by Domas |
| Buffer Overflow, Race Condition, Input Validation, Format String | :star::star::star::star: | by Wenliang (Kevin) Du |
| Meltdown | :star::star::star::star: | by Lipp, Schwarz, Gruss, Prescher, Haas, Mangard, Kocher, Genkin, Yarom, and Hamburg |
| Basic Linux Privilege Esclation | :star::star::star: | by g0tmi1k |
| **Network Protocol Fuzzing and Buffer Overflow | :star::star::star::star: | by Joey Lane |
| Secure Programming HOWTO | :star::star::star: | by David A. Wheeler |
| Padding the struct | :star::star::star: | by NCC Group |
| Efficiently Generating Python Hash Collisions | :star::star: | |
| Stochastic Process Wikipedia | :star::star: | |
| Gimli: a cross-platform permutation | :star::star: | |
| LiveOverflow | :star::star: |
**[Forum cracks the vintage passwords of Ken Thompson and other Unix pioneers](https://arstechnica.com/information-technology/2019/10/forum-cracks-the-vintage-passwords-of-ken-thompson-and-other-unix-pioneers/)**
**[Most Common Chess Openings](https://www.thesprucecrafts.com/most-common-chess-openings-611517)**
**[Kasparov Miniature and Tactics/Endgames | Kids' Class - GM Varuzhan Akobian](https://www.youtube.com/watch?v=_B39II74Pkc)**
When in doubt, use bruteforce ― Ken Thompson
Programming is not a zero-sum game. Teaching something to a fellow programmer doesn't take it away from you. I'm happy to share what I can, because I'm in it for the love of programming ― John Carmack
| Title | How Interesting | Author |
|---|---|---|
| SDL2 Tutorial | :two_hearts: | by mysterious Lazyfoo |
| The Book of Shaders | :two_hearts: | by Patricio Gonzalez Vivo & Jen Lowe |
| Fast Inverse Square Root | :two_hearts: | attributed to John Carmack (Quake III) |
| Game Engine Architecture | :star::star::star::star::star: | by Jason Gregory |
| Introduction to Computer Graphics | :star::star::star::star::star: | by Justin Solomon |
| RayCasting Tutorial + Source Code | :star::star::star::star::star: | by Lodev |
| Shaders Programming | :star::star::star::star: | by Hitesh Sahu |
| Coding Minecraft in two days (source code)[https://github.com/jdah/minecraft-weekend] | :star::star::star::star::star: | by Jdah |
| ** | Moving Frostbite to Physically Based Rendering 3.0** | :star::star::star::star: |
| 3d Fractal Flame Wisps | :star::star::star: | by Yujie Shu |
| Geometry Caching Optimizations in Halo 5 | :star::star::star: | by Zabir Hoque and Ben Laidlaw |
| Physically-Based Shading at Disney | :star::star::star: | by Brent Burley, Walt Disney Animation Studios |
| Light and Shadows in Graphics | :star::star: | by Tom Scott |
| Screen Space Ambient Occlusion Tutorial | :star::star: | by Tom Scott |
| Exponentiation by Squaring | :star: | Wikipedia |
It is through science that we prove, but through intuition that we discover ― Henri Poincaré
| Title | How Interesting | Author |
|---|---|---|
| OpenCV Tutorial | :star::star::star: |
C++ is a horrible language. It's made more horrible by the fact that a lot of substandard programmers use it, to the point where it's much much easier to generate total and utter crap with it ― Linus Torvalds 2007
| Title | How Interesting | Author |
|---|---|---|
| Optimizing software in C++ | :two_hearts: | by Agner Fog |
| Intel Intrinsics Guide What is it | :two_hearts: | Intel |
| Software Performance and Indexing | :two_hearts: | by Daniel Lemire |
| "Low Latency C++ for Fun and Profit" | :star::star::star::star: | by Carl Cook |
| Why I Created C++ | :star::star::star: | Bjarne Stroustrup |
| CppCon 2018 “High-Radix Concurrent C++” | :star::star::star: | Olivier Giroux |
| C++ Features | :star::star::star: | by Anthony Calandra |
People say that you should not micro-optimize. But if what you love is micro-optimization... that's what you should do ― Linus Torvalds
| Title | How Interesting | Author |
|---|---|---|
| Intel® 64 and IA-32 architectures software developer’s manual | :two_hearts: | Intel |
| Optimizing subroutines in assembly x86 language | :two_hearts: | by Agner Fog |
| Online Compiler Explorer | :star::star::star::star::star: | by Godbolt |
| Online Assembler and Disassembler | :star::star::star::star: | by Taylor Hornby |
| A Guide to inline assembly for C and C++ | :star::star::star::star: | by Salma Elshatanoufy and William O'Farrell |
| Tips for Golfing in x86/x64 Bytecode | :star::star::star: | by StackExchange |
| The Art of Assembly Language | :star::star: | by Randal Hyde |
| GDB Tutorial | :star::star: | by Andrew Gilpin |
| Examining Arm VS x86 Memory Models with Rust | :two_hearts: | by Nick Wilcox |
A monad is just a monoid in the category of endofunctors, what's the problem? ― James Iry
| Title | How Interesting | Author |
|---|---|---|
| Learn You a Haskell for Great Good! | :two_hearts: | by Miran Lipovača |
| Functors, Applicatives, And Monads In Pictures | :two_hearts: | by Aditya Bhargava |
| Category Theory course by Bartosz Milewski | :star::star::star::star::star: | by Bartosz Milewski |
| Wise Man's Haskell | :star::star::star::star: | by Andre Popovitch |
| Real World Haskell | :star::star::star: | by Bryan O'Sullivan |
| Martin Odersky's Scala course | :star::star: | by Martin Odersky |
And luckily right at that moment my wife went on a 3 weeks vacation to take my one year old (roughly) to visit my in-laws who were in California, this period long, 1 week, 1 week, 1 week... and we had Unix ― Ken Thompson, VCF East 2019
| Title | How Interesting | Author |
|---|---|---|
| Digital Design and Computer Architecture | :star::star::star::star: | ** |
| X86 vs ARM | :star::star::star: | Fossbytes |
| MIPS Processors | :star::star: | Stack Overflow |
...and Unix is an example of a proper name, and, is not likely to be in the dictionary ever ― Brian W. Kernighan (1982)
| Title | How Interesting | Author |
|---|---|---|
| AVIF for Next Generation Image Coding | :star::star::star::star::star: | By Aditya Mavlankar, Jan De Cock, Cyril Concolato, Kyle Swanson, Anush Moorthy and Anne Aaron |
| UNIX AT&T Archives film from 1982 | :two_hearts: | by Bell Laboratories |
| A Super Mario 64 decompilation | :star::star::star::star::star: | by a bunch of clever folks |
| The Go Programming Language | :star::star::star::star::star: | by Alan A. A. Donovan and Brian W. Kernighan |
| Vim 101 Quick Movement | :star::star::star::star: | Alex R. Young |
| Software Version Control Visualization : :star::star::star::star: | by Andrew Caudwell | |
| Math for Game Programmers: Dark Secrets of the RNG | :star::star::star: | by Shay Pierce |
| Clean Code | :star::star::star: | by Robert C. Martin |
| Why Java Suck | :star: | by Jonathan Gardner |
| XOR Linked List – A Memory Efficient Doubly Linked List | :star: | Wikipedia |
| XOR Linked List – C Implementation | :star: | StackOverFlow |
| Title | How Interesting | Author |
|---|---|---|
| Framework: Flutter Hello World | :two_hearts: | by Flutter Team (Google) |
| Images: About Webp | :star::star: | Suzanne Scacca |
To succeed, planning alone is insufficient. One must improvise as well ― Isaac Asimov, Foundation
| Format | Title | How Interesting | Author |
|---|---|---|---|
| Book | The Foundation | :two_hearts: | by Isaac Asimov |
| Book | The Hitchhiker's Guide to the Galaxy | :two_hearts: | by Douglas Adams |
| AudioBook | The Hitchhiker's Guide to the Galaxy | :two_hearts: | by Douglas Adams and read by Stephen Moore |
| Movie | Ready Player One | :two_hearts: | by Steven Spielberg |
| Movie | Matrix | :two_hearts: | by the Wachowskis |
| Book | Hyperion | :star::star::star::star: | by Dan Simmons |
| Movie | War Games | :star::star::star: | directed by John Badham |
| Book | Elon Musk Biography | :star::star::star::star::star: | by Ashlee Vance |
<img src="http://img.youtube.com/vi/Jen46qkZVNI/0.jpg"
alt="Boxer's Perfect Rush SCV" width="240" height="180" border="10" />
When you want to aim for lowest latency - i.e maximum speed - there are many things that will improve your program to create a better binary: Optimization flag, parallelization, vectorization and carefully crafting your algorithm.
Especially for Computer Graphics projects, you will want to turn on these optimization flags, listed on gcc website.
Without any optimization option, the compiler’s goal is to reduce the cost of compilation and to make debugging produce the expected results. Statements are independent: if you stop the program with a breakpoint between statements, you can then assign a new value to any variable or change the program counter to any other statement in the function and get exactly the results you expect from the source code.
Turning on optimization flags makes the compiler attempt to improve the performance and/or code size at the expense of compilation time and possibly the ability to debug the program.
To use it simply compile the program with:
gcc -O2 a.cNB: It is the letter 'o' and not a zero. You may also use O3.
The historical (and current) approach is to add more power via multithreading, multiprocessing, Grid Computing or even Cloud Computing. Two libraries exist for this use: OpenMP and pthread, you will have to compile respectively with:
gcc -fopenmp -O3 a.cand:
gcc -pthread -O3 a.cModern graphics processing units (GPUs) are often wide SIMD implementations, capable of branches, loads, and stores on 128 or 256 bits at a time.
Intel's latest AVX-512 SIMD instructions now process 512 bits of data at once.
As a double is 64 bits - i.e 8 bytes or octets - instead of iterating overs value 1 by 1, you will be able to compute up to 8 double at the time - i.e 512 / 64 - if your computer support it (but most likely, as of 2020, your computer will only handle 256 bits register).
Vectorization the most efficient way to quickly gain performance gains without the overhead of threads' initialization.
Demonstration: Getting Min and Max value from a float array
/* Vectorization example by agavrel */
#include <stdio.h> // printf
#include <stdlib.h> // rand()
#include <time.h> // time
#include <xmmintrin.h> // 128 bits register _m128
float m128_max_float(__m128 src) {
__m128 n[4];
// a) n[0] = src >> 64 So lets say src is composed of floats a b c d, it becomes 0 0 a b
n[0] = _mm_shuffle_ps(src, src, _MM_SHUFFLE(0,0,3,2));
// b) n[1] = {max(a,0), max(b,0) max(a,c) max(b,d)} NB: actually we don't care about the two highest float at this point, I will call them 'x': {x, x max(a,c) max(b,d)}
n[1] = _mm_max_ps(src, n[0]);
// c) n[2] = n[1] >> 32 So n2 become {0 x x max(a,c)}
n[2] = _mm_shuffle_ps(n[1], n[1], _MM_SHUFFLE(0,0,0,1));
// d) n[3] = {x x x max(max(a,c), max(b,d))}
n[3] = _mm_max_ps(n[1], n[2]);
return _mm_cvtss_f32(n[3]); // d) Hence max(a,b,c,d), stored in the lowest 32 bits of n[3], is loaded into a float that we return. We don't care about the other bits
}
float m128_min_float(__m128 src) {
__m128 n[4];
n[0] = _mm_shuffle_ps(src, src, _MM_SHUFFLE(0,0,3,2));
n[1] = _mm_min_ps(src, n[0]);
n[2] = _mm_shuffle_ps(n[1], n[1], _MM_SHUFFLE(0,0,0,1));
n[3] = _mm_min_ps(n[1], n[2]);
return _mm_cvtss_f32(n[3]);
}
#define SIZE 1000000000L // 1 billion. Yes.
void get_min_max(long i, float array[i]) {
__m128 max;
__m128 min;
max = _mm_loadu_ps(array); // will load first 4 float into max
min = _mm_loadu_ps(array); // will load first 4 float into min
while ((i -= 4L))
{
__m128 tmp = _mm_loadu_ps(array + i);
max = _mm_max_ps(max, tmp);
min = _mm_min_ps(min, tmp);
}
printf("Max value: %f\t Min value: %f\n", m128_max_float(max), m128_min_float(min));
}
void get_min_max_like_bocalian(long size, float array[size]) {
float max;
float min;
int i;
max = array[0];
min = array[0];
i = 1L;
while (i < size)
{
float tmp = array[i++];
max = tmp < max ? max : tmp;
min = tmp > min ? min : tmp;
}
printf("Max value: %f\t Min value: %f\n", max, min);
}
int main()
{
long i;
float *data;
clock_t time;
srand(time(NULL)); // seed
data = (float *)malloc(SIZE * sizeof(float));
i = -1L;
while (++i < SIZE) {
data[i] = (float)rand() / (float)(RAND_MAX) * 1000.0f;
/* printf("%.02f\t\t", data[i]); // I commented these lines because it slows considerably the program.
if (!(i & 15))
printf("\n");*/
}
time = clock();
get_min_max(SIZE, data);
time = clock() - time;
double elapsed_time = ((double)time) / CLOCKS_PER_SEC;
printf("Executed in %f seconds\n", elapsed_time);
time = clock();
get_min_max_like_bocalian(SIZE, data);
time = clock() - time;
elapsed_time = ((double)time) / CLOCKS_PER_SEC;
printf("Executed in %f seconds\n", elapsed_time);
return 0;
}And compile with:
gcc vectorization.c -O3 && ./a.out You will notice that the vectorized approach will be about 3 times faster (NB: For this specific example). If I was using mm256 or mm512 registers, the vectorized program would be even faster by a factor of 2 and 4 respectively.
Now that you realize the performance boost, how about using what you just learn for your RayTracing project?
a) You can take a look at this very interesting project which aim to show how fast wc can get using the various tools C has to offer to optimize speed. After downloading the file, you will also need to download the header: simd.h, which make use of Intel intrinsic.
b) Compile it with the flags:
gcc fastlwc-mt.c -fopenmp -O3c) Create a random file:
dd if=/dev/urandom of=sample.txt bs=64M count=16 iflag=fullblockd) Compare wc with the new binary with:
time ./a.out sample.txt \
&& time wc sample.txtThe right algorithm is usually the corner stone of an efficient program.
How about solving this algorithm problem:
int32_t dancer_position(uint32_t time_elapsed) { ;}Let's take and example with the brilliant UTF-8 implementation, especially at how continuation bytes are designed:
continuation bytes start with 10 while single bytes start with 0 and longer lead bytes start with 11
Let's say that you have to write a function that determines if the byte is a continuation one, you can think of many ways that would end with the same result. But they will have a different output in their assembly.
You can retain the two first bits wwith & 0b11000000` and then make sure that the first one is set and the second one is not with `== 0b10000000
#include <stdbool.h>
bool is_utf8_continuation_byte(char c) {
return ((c & 0b11000000) == 0b10000000);
}Which corresponds to the following compiler output with gcc x86-64 9.3 with -O3 optimization flag
and edi, 192
cmp edi, 128
sete alAnother way would be to shift the bits to the right:
bool is_utf8_continuation_byte(char c) {
return (!((((unsigned char)c >> 6) ^ 0b10)));
}Here I cast c into unsigned in order to be able to shift the MSB to the right with (unsigned char)c
Then I shift it 6 times to the right with >> 6
Finally I xor the result by 0b10 with ^ 0b10
As a number xored by itself gives 0, I use the exclamation mark ! to reverse the result from 0 to 1. (Else we would have to rename the function is_not_utf8_continuation_byte
It is not producing the following output that you could imagine:
sar edi, 6
xor edi, 2
not edi,But the optimized version:
movzx edi, dil
sar edi, 6
cmp edi, 2
sete alIt's even less efficient.
Finally since the valid range 0b10111111 to 0b10000000 (corresponding to -128 to -65, both included), you can add 0b01000000 and check if the byte is negative:
bool is_utf8_continuation_byte(char c) {
return (c + 0b01000000 < 0);
}In other word you compare to -64 and check if it is lower:
cmp dil, -64
setl alTo see the assembly output you can use the following command which will generate an assembly file with intel syntax (more readable than AT&T):
gcc -O3 -S -masm=intel a.c && cat a.sor use the excellent compiler explorer from godbolt
I hope that you liked this demonstration that shows that functions with same behaviors can produce different assembly output, hence being more or less efficient. If you want to build your program to be the most efficient you should explore the assembly code of functions in critical loops
You can follow tutorials to create a simple program with SDL on Lazyfoo's website or on SDL2 official website.
You will also have to install SDL2:
brew install sdl2With SDL2 you have to first init_sdl` - *see function below*. Then you will keep the user entertained with a loop `while (42)` that can only be escaped by clicking on the the close button or pressing escape. While the loop is active, user's actions will be recorded thanks to `SDL_PollEvent`. You then draw pixel by using `SDL_RenderDrawPoint` and you refresh image with `SDL_RenderPresent
Michael Barnsley was a British mathematician who coined a fractal algorithm to represent a fern.

The algorithm is explained in detail on wikipedia
Find below the code for the whole program, compile it with :
gcc barnsley.c -lSDL2 -O3You will need about 10 000 iterations of n to draw the shape. On each keypress you will increase the number of iterations by 400.
#pragma message "\033[1;31mRequire SDL2\033[0m, \033[1;92mbrew install sdl2\033[0m and compile with \033[1;5;36mgcc barnsley.c -lSDL2\033[0m && ./a.out " __FILE__ "..."
// gcc main.c -lSDL2 -O3 -Wall -Werror -Wextra --pedantic&& ./a.out
#include <stdio.h>
#include <SDL2/SDL.h>
#include <stdbool.h>
#define WINDOW_WIDTH 600
#define WINDOW_HEIGHT 800
typedef struct s_cnb
{
double real;
double imag;
} t_cnb;
typedef struct s_pixel
{
int x;
int y;
} t_pixel;
void barnsley(SDL_Renderer *renderer, t_cnb *c) {
float rng;
t_pixel i;
static const float probability[3] = {0.01f, 0.08f, 0.15f};
long n = 400;
while (n--) {
rng = ((float)rand() / (float)RAND_MAX);
if (rng <= probability[0]) {
c->real = 0;
c->imag *= 0.16f;
}
else if (rng <= probability[1]){
c->real = -0.15f * c->real + 0.28f * c->imag;
c->imag = 0.26f * c->real + 0.24f * c->imag + 0.44f;
}
else if (rng <= probability[2]) {
c->real = 0.2f * c->real + -0.26f * c->imag;
c->imag = 0.23f * c->real + 0.22f * c->imag + 1.6f;
}
else {
c->real = 0.85f * c->real + 0.04f * c->imag;
c->imag = -0.04f * c->real + 0.85f * c->imag + 1.6f;
}
i.x = (c->real + 3) * 70;
i.y = WINDOW_HEIGHT - c->imag * 70;
SDL_RenderDrawPoint(renderer, i.x, i.y);
}
}
bool error_sdl(char *error_msg) {
printf( "%s! SDL_Error: %s\n", error_msg, SDL_GetError() );
return false;
}
bool init_sdl(SDL_Window **window, SDL_Renderer **renderer) {
if (SDL_Init(SDL_INIT_VIDEO) < 0)
return (error_sdl("SDL could not initialize!"));
SDL_CreateWindowAndRenderer(WINDOW_WIDTH, WINDOW_HEIGHT, 0, window, renderer);
if (*window == NULL)
return (error_sdl("Window could not be created!"));
SDL_SetRenderDrawColor(*renderer, 0, 0, 0, 0);
SDL_RenderClear(*renderer);
SDL_SetRenderDrawColor(*renderer, 0xbf, 0xff, 0, 0);
return true;
}
int main(void) {
SDL_Event event;
SDL_Window *window;
SDL_Renderer *renderer;
t_cnb c;
if (!(init_sdl(&window, &renderer)))
return 1;
c = (t_cnb) {.real = 0, .imag = 0}; // PS: legal for Norminette
while (42) {
if (SDL_PollEvent(&event)) {
if (event.type == SDL_QUIT)
break ;
else if (event.type == SDL_KEYDOWN) {
if (event.key.keysym.sym == SDLK_ESCAPE)
break ;
barnsley(renderer, &c);
SDL_RenderPresent(renderer);
}
}
}
SDL_DestroyRenderer(renderer);
SDL_DestroyWindow(window);
SDL_Quit();
return EXIT_SUCCESS;
}Let's take a look at the function strcpy, shall we? Type man strcpy
The strcpy() function copies the string pointed to by src, including the terminating null byte ('\0'), to the buffer pointed to by dest. The strings may not overlap, and the destination string dest must be large enough to receive the copy. Beware of buffer overruns! (See BUGS.)
NB: Usage of brackets for what is considered as one of the most critical security flaw in the world
BUGS:
If the destination string of a strcpy() is not large enough, then anything might happen ― NB: Undefined Behavior. Overflowing fixed-length string buffers is a favorite cracker technique for taking complete control of the machine. Any time a program reads or copies data into a buffer, the program first needs to check that there's enough space. This may be unnecessary if you can show that overflow is impossible, but be careful: programs can get changed over time, in ways that may make the impossible possible.
#include <string.h>
#include <stdio.h>
int main(void) {
char s[11];
strcpy(s, "hello world");
puts(s);
return 0;
}While this look okay if you count each letter, if you happen to read again the definition of strcpy (just above) you will notice:
including the terminating null byte ('\0')
So you are trying to copy 12 characters in fact, into a 11 characters buffer. You will get the nice message:
In function ‘main’:
warning: ‘__builtin_memcpy’ writing 12 bytes into a region of size 11 overflows the destination [-Wstringop-overflow=]
strcpy(s, "hello world");In fact all functions that you will find in #include <banned.h>
#include <stdio.h>
#include <string.h> // for strcmp, compare two strings and return 0 if they are equal
char *strcpy_until(char *dst, char *src, char until)
{
int i = -1;
while (src[++i] != until)
dst[i] = src[i];
return (dst);
}
int main(int ac, char **av) {
int n = 5;
char password[] = "sarang hae"; // we don't know
char buffer[4] = "kkk";
if (ac != 2)
return 1;
printf("n equals %d\n", n);
printf("you would have never guessed, password was '%s'\n\n", password);
char *s = &buffer[3];
char shellcode[] = "\x42\x61\x67\x61\x76\x72\x65\x6c\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x2a\x00\x00\x01";
strcpy_until(s, shellcode, '\x01');
printf("n equals '%d'\n", n);
printf("password now equals: '%s'\n", password);
if (!strcmp(password, av[1])) {
printf("\nSuccessfully hacked user with password \e[1;5;92m%s\e[0m\n", password);
}
return 0;
}Would you have guessed the password?
Some explanations:
strcpy_untilchar shellcode[]When something is important enough, you do it even if the odds are not in your favor ― Elon Musk
You will now have to compile with:
gcc -fno-stack-protector -z execstack a.c-fno-stack-protector a.c-z execstackLast you will also temporarily disable randomize va space with:
sudo sysctl -w kernel.randomize_va_space=0NB: You can use safer method setarch uname -m -R /bin/bash
Once done with experiments do not forget to set back randomize back to normal:
sysctl -a --pattern "randomize" && \
sudo sysctl -w kernel.randomize_va_space=2{WIP}
Often you will have programs where you want to represent data the following way:
int map[8][8];While it looks like it is convenient, you can make it convenient using the right functions. But if you are using an integer to tell if the board is filled with pieces, you are wasting a lot of memory.
#include <iostream>
#include <map>
using namespace std;
void print_binary(uint64_t n)
{
uint64_t mask = 0;
for (mask = ~mask ^ (~mask >> 1); mask != 0; mask >>= 1)
putchar('0' + !!(n & mask));
putchar('\n');
}
void fill_board(uint64_t board[12], uint64_t *used_cells)
{
const uint64_t initial_pos[6] = { 0b0000000011111111000000000000000000000000000000001111111100000000, // most right is a1, most left is h8
0b1000000100000000000000000000000000000000000000000000000010000001,
0b0100001000000000000000000000000000000000000000000000000001000010,
0b0010010000000000000000000000000000000000000000000000000000100100,
0b0001000000000000000000000000000000000000000000000000000000001000,
0b0000100000000000000000000000000000000000000000000000000000010000
};
const uint64_t color_mask[2] = { 0b0000000000000000000000000000000011111111111111111111111111111111,
0b1111111111111111111111111111111100000000000000000000000000000000
};
*used_cells = 0;
for (int i = 0; i < 12; i++) {
board[i] = (initial_pos[i >> 1]) & (color_mask[i & 1]);
*used_cells |= board[i];
}
}
void display_board(uint64_t board[12])
{
for (int i = 0; i < 12; i++)
print_binary(board[i]);
}
std::map<string, uint64_t> fill_move() {
std::map<string, uint64_t> move;
for (char r = '1'; r <= '8'; r++) {
for (char c = 'a'; c <= 'h'; c++) {
char cell[3] = {c, r, '\0'};
move[cell] = (1UL << (8 * (c - 'a'))) << (r - '1');
}
}
return move;
}
enum PIECE {
__PAWN_W = 0,
__PAWN_B,
__ROOK_W,
__ROOK_B,
KNIGHT_W,
KNIGHT_B,
BISHOP_W,
BISHOP_B,
_QUEEN_W,
_QUEEN_B,
__KING_W,
__KING_B = 11
};
int main()
{
uint64_t board[12];
uint64_t used_cells;
std::map<string, uint64_t> move = fill_move();
fill_board(board, &used_cells);
display_board(board);
putchar('\n');
print_binary(board[__PAWN_W]);
if (board[__PAWN_W] & move["b4"]) // check if exist
board[__PAWN_W] ^= ((move["b4"] | move["e4"]));
print_binary(board[__PAWN_W]);
putchar('\n');
return 0;
}If you know how to make software, then you can create big things ― Xavier Niel
One function related to each 42 project to help students get started
In-depth examples with pointers
Books on system design
Exemple of a Makefile "qui fait le cafe"
I think it's very important to have a feedback loop, where you're constantly thinking about what you've done and how you could be doing it better ― Elon Musk
Raise an issue or even better: submit a pull request
First fork the repository and clone it locally (you will be forgiven for this kind of git clone)
Make the desired changed to the README.md file
Then open the terminal containing your fork and enter:
git checkout -b agavrel
git commit -am "[ADD] Interesting link about C Hash"
git push --set-upstream origin agavrelGo back to internet and you will see that you can submit a pull request.
I will personally review contributions
Show your appreciation by starring the repo, sharing on slack, RT and 'lache un com magueule' skyblog™

잘했어 동무 계속 배우자 ― Good Job Comrade, let's keep studying
Antonin GAVREL
Feel free to reach me on LinkedIn
// Doxygen documentation generator set
// 文件注释:版权信息模板
"doxdocgen.file.copyrightTag": [
"@copyright Copyright 2009 - 2021, xxx Technology Ltd.",
"-----------------------------------------------------------------",
"Statement:",
"----------",
"xxx",
"-----------------------------------------------------------------",
],
"doxdocgen.file.customTag": [
"-----------------------------------------------------------------",
"*/\n\n/*",
"//***********************",
"//Head Block of The File",
"//***********************",
"#ifndef _XXX_H_",
"#define _XXX_H_\n\n",
"#ifdef __cplusplus",
"extern \"C\" {",
"#endif\n\n",
"//Sec 0: Comment block of the file\n\n",
"//Sec 1: Include File\n\n",
"//Sec 2: Constant Definitions, Imported Symbols, miscellaneous\n\n",
"//******************************",
"//Declaration of data structure",
"//******************************",
"//Sec 3: structure, uniou, enum, linked list\n\n",
"//********************************************",
"//Declaration of Global Variables & Functions",
"//********************************************",
"//Sec 4: declaration of global variable\n\n",
"//Sec 5: declaration of global function prototype\n\n",
"//***************************************************",
"//Declaration of static Global Variables & Functions",
"//***************************************************",
"//Sec 6: declaration of static global variable\n\n",
"//Sec 7: declaration of static function prototype\n\n",
"//***********",
"//C Functions",
"//***********",
"//Sec 8: C Functions\n\n\n\n",
"#ifdef __cplusplus",
"}",
"#endif\n",
"#endif\n",
],
// 文件注释的组成及其排序
"doxdocgen.file.fileOrder": [
"copyright", // 版权
"file", // @file
"brief", // @brief 简介
"author", // 作者
//"version", // 版本
"date", // 日期
//"empty", // 空行
"custom", // 自定义
],
// 下面时设置上面标签tag的具体信息
"doxdocgen.file.fileTemplate": "Filename:\n-------------\n@file {name}\n",
"doxdocgen.generic.briefTemplate": "@brief xxx这里描述文件或者函数的功能\n",
"doxdocgen.file.versionTag": "@version 1.0",
"doxdocgen.generic.authorEmail": "xxx@xxx.com",
"doxdocgen.generic.authorName": "xxx",
"doxdocgen.generic.authorTag": "Author:\n---------\n@author {author}({email})\n",
// 日期格式与模板
"doxdocgen.generic.dateFormat": "YYYY-MM-DD",
"doxdocgen.generic.dateTemplate": "Create time:\n---------\n@date {date}",
// 根据自动生成的注释模板(目前主要体现在函数注释上)
"doxdocgen.generic.order": [
"brief",
"tparam",
"param",
"return"
],
"doxdocgen.generic.paramTemplate": "@param{indent:8}{param}{indent:2} ",
"doxdocgen.generic.returnTemplate": "@return {type} ",
"doxdocgen.generic.splitCasingSmartText": true,
"doxdocgen.c.commentPrefix": "",
"[cpp]": {
"editor.defaultFormatter": "xaver.clang-format"
},添加或者修改:
SOURCE_BROWSER = NO
VERBATIM_HEADERS = NO
vsc的输出框中显示:
无法使用 xxx解析配置
很糟心,查了半天也没有结果。
最后才明白:
原来是意思是这个xxx无法识别,而不是值不对(这个xxx是从以前的环境中同步过来的,可能已经不兼容字段了)。
解决方法:
就是把这个字段所在的.vscode\xxxxxx.json给删了,其实只删除这个不识别的字段应该也是可以的。
方法1:
git reset --soft HEAD^这样就成功撤销了commit,如果想要连着add也撤销的话,–soft改为–hard(删除工作空间的改动代码)。
命令详解:
HEAD^ 表示上一个版本,即上一次的commit,也可以写成HEAD~1
如果进行两次的commit,想要都撤回,可以使用HEAD~2
–soft
不删除工作空间的改动代码 ,撤销commit,不撤销git add file
–hard
删除工作空间的改动代码,撤销commit且撤销add
方法2:
git commit --amend进入vim后,正常编辑后wq退出
现象:keil明明安装在D盘,但是编译某个工程时,一直提示找不到c盘的路径
检查:
项目右键-》 options for target-》user-》after build/rebuild -》run
检查路径值,如果是脚本,检查脚本的里面的内容
以下介绍几种常见的嵌入式中使用的无侵入二次开发方式:
代表就是阿里的haas:https://help.aliyun.com/document_detail/266803.html
下载的是脚本或者编译后的生成文件。
代表就是合宙的openlua:
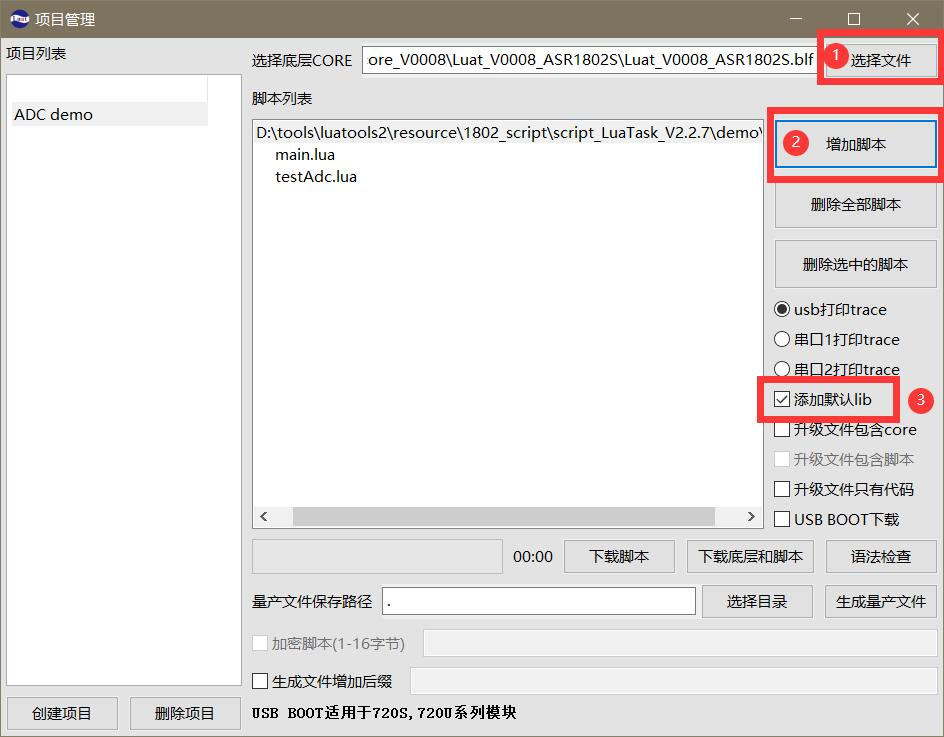
https://doc.openluat.com/article/713/0#%E7%83%A7%E5%BD%95Lua%E8%84%9A%E6%9C%AC
下载的是lua脚本。
代表就是移远的QuecPython:
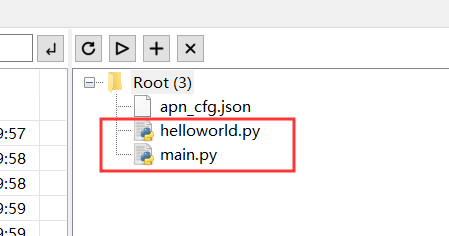
https://python.quectel.com/doc/doc/Quecpython_intro/zh/Qp_Hw_EC600X/Hardware_Support_EC600X.html
下载的是Python脚本。
大家在做ble相关开发时,经常看到芯片的规格或者app的描述时,出现slave,master,server,client这些名词,那么这些名词到底是什么意思,有什么关系?
另外:从协议栈能力本身来说,master和slave是可以并存的,一个设备既可以广播,也可以接收他人的广播。
ref:https://docs.silabs.com/bluetooth/2.13/general/connections/master-and-slave-roles
linux 设备中经常看到 CONFIG_OF 或者 OF,表示什么意思?
这个是Open Firmware Device Tree 的简称,有时也简称 DT。
OF 是 CONFIG_OF的简称
详细参见: https://www.kernel.org/doc/Documentation/devicetree/usage-model.txt
google pixel 原版系统。
对于有洁癖的人来说,有时候我们会非常想关闭负一屏的默认的各种乱七八糟的新闻,怎么关闭?
点击google账号头像,进入个人中心,设置 => 常规 => 探索,关闭探索按钮。
清净了,舒服!
欲望,本身是一个中性词,他可以代指世间一切的追求和念想。
人是被欲望支配的动物,一个没有欲望的人是会死掉的。我们日常的各种行为和决策,从根本上讲,其实都是围绕我们的欲望开展的。
认知自我是最难的事情,因为要客观认知,就意味着要否定和肯定并存,而否定自我是大部分人做不到的,进一步说大部分人无法找到否定自我后进一步的进取对策,找到它的积极意义。
我们要正确认知自我,才能保证我们对自己做出正确的评估和人生决策,才能指导我们对现实世界的事务目标做出正确决策和评估,才能保证我们有能力落地实施,最终达成目标,创造美好生活。
这种认知不仅需要对自我经历的思考,也需要结合社会科技人文的动向和社会需求来进行。能正确理解当今的社会现状和事实,具备基本的知识,以此为标准对自我进行分析和反思。
认知自我是我们制定人生目标的前提,是我们行动的参考,在我们做任何决策和行动前,我们都应该先清楚认知自我的内心,能力和欲望。
认知自我也是我们克服焦虑的唯一方法。
新拿到的pixel3原系统,发现wifi连接后受限,4g lte也无法打开网页,提示SSl相关的问题。
找到的解决方法:
没有ROOT情况 (adb命令要自行安装与配置)
没有 ROOT 的安卓机可以借助 ADB 命令来修改,首先下载ADB工具包,然后手机开启USB调试模式,接着运行 CMD 输入下面的命令就可以了。
# 删除默认的地址
adb shell settings delete global captive_portal_https_url
adb shell settings delete global captive_portal_http_url
# 修改新的地址
adb shell settings put global captive_portal_http_url http://captive.v2ex.co/generate_204
adb shell settings put global captive_portal_https_url https://captive.v2ex.co/generate_204
改完同样把手机切换飞行模式,再切换回来就可以了。如果需要其它服务器地址,自行修改,如 MIUI 的是 http://connect.rom.miui.com/generate_204 地址最近对ThreadX很感兴趣,TreadX官方文档中有Silicon Labs EFR32MG12的代码支持,我手头没有这块板子,但我之前有幸拿到了朋友送的配置可谓极致的silicon labs BG22开发板,所以想尝试下这个板子是否也可以用。
这个板子可谓精致,还有配套的演示app,可玩性很高,但是一直忙于其他项目,没有时间研究。所以趁国庆有空,拿出来吃灰的板子研究下,希望以后能有机会拿它在高端和超低功耗场景拿来做产品,同时也算是对朋友的一个交代。
万事开头难,我们要怎么快速入门silicon labs的系列产品呢?对于c类型项目来说,最难的入门门槛就是开发环境和开发流程,搞定这些,到了纯编码部分就是很快的事情了。
本文内容分为以下几个部分:
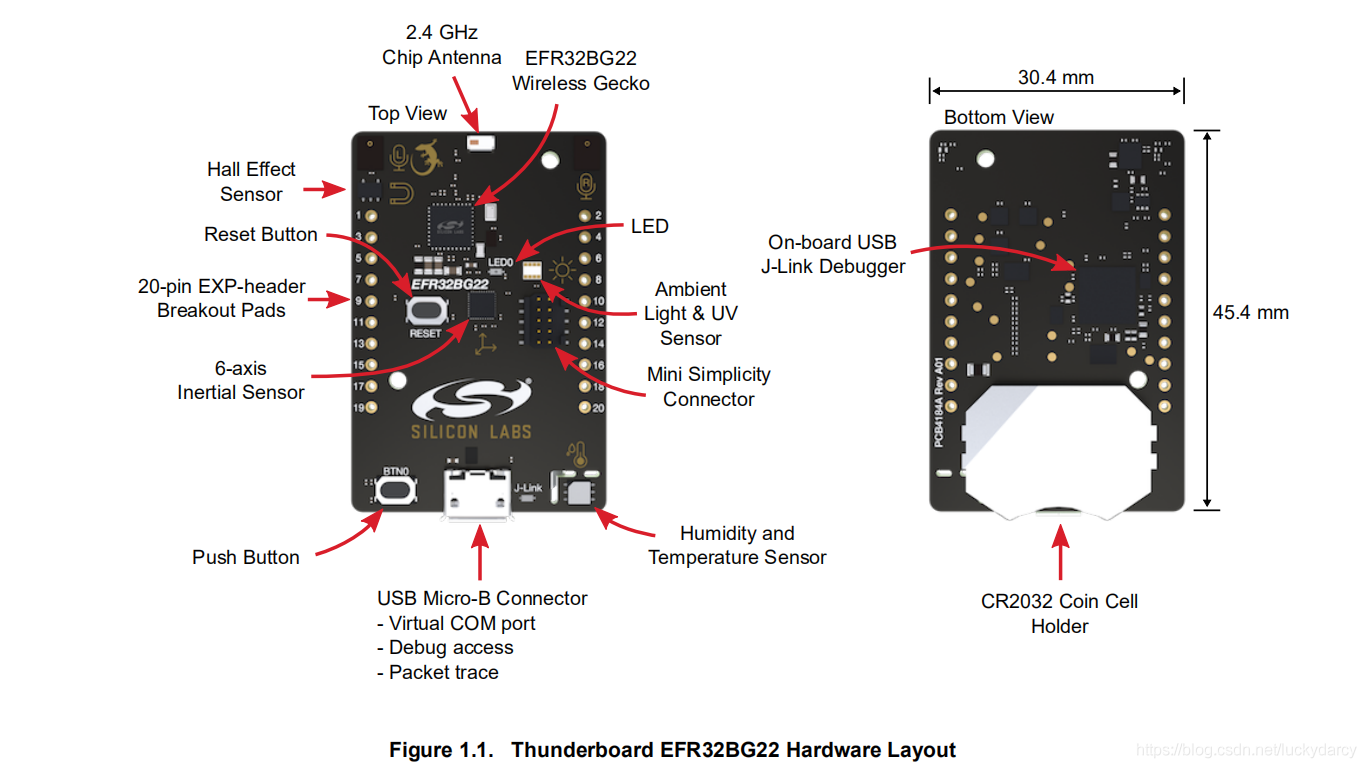
小封装 Thunderboard
除了左右两个MIC,以上的传感器和按键以及led都在APP中可以互通。
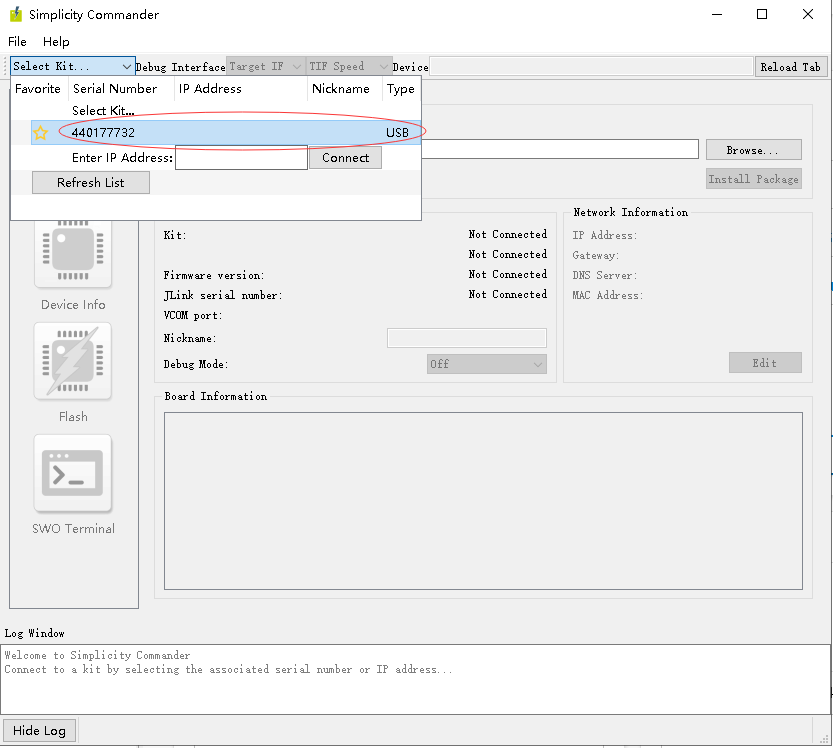
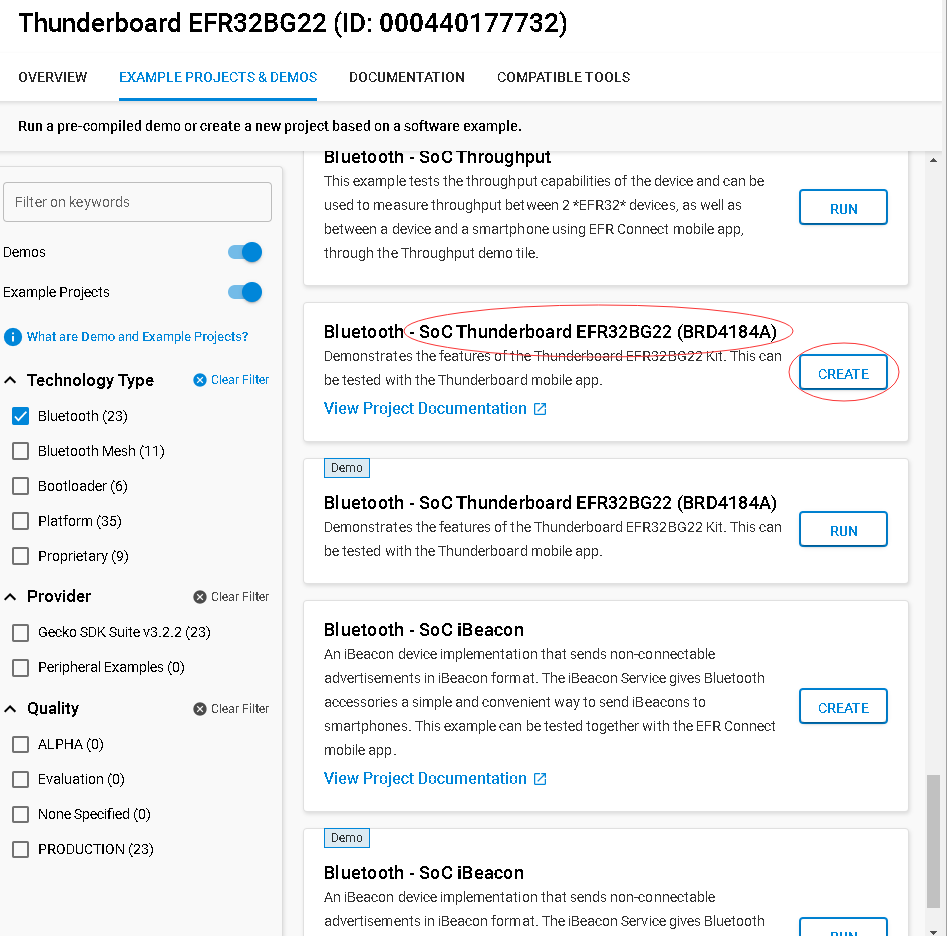
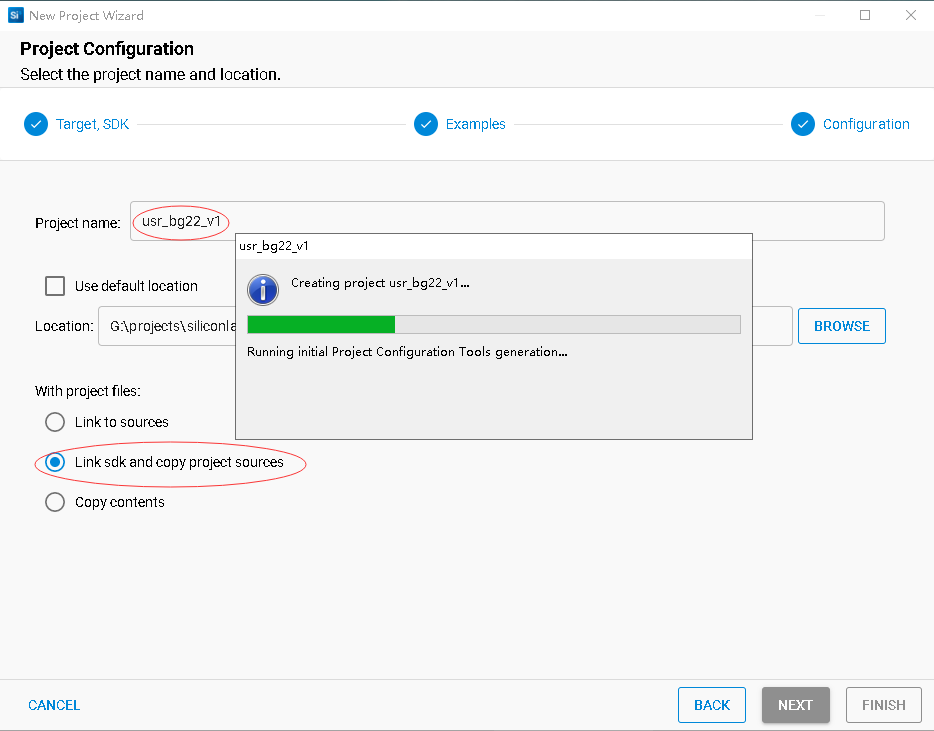
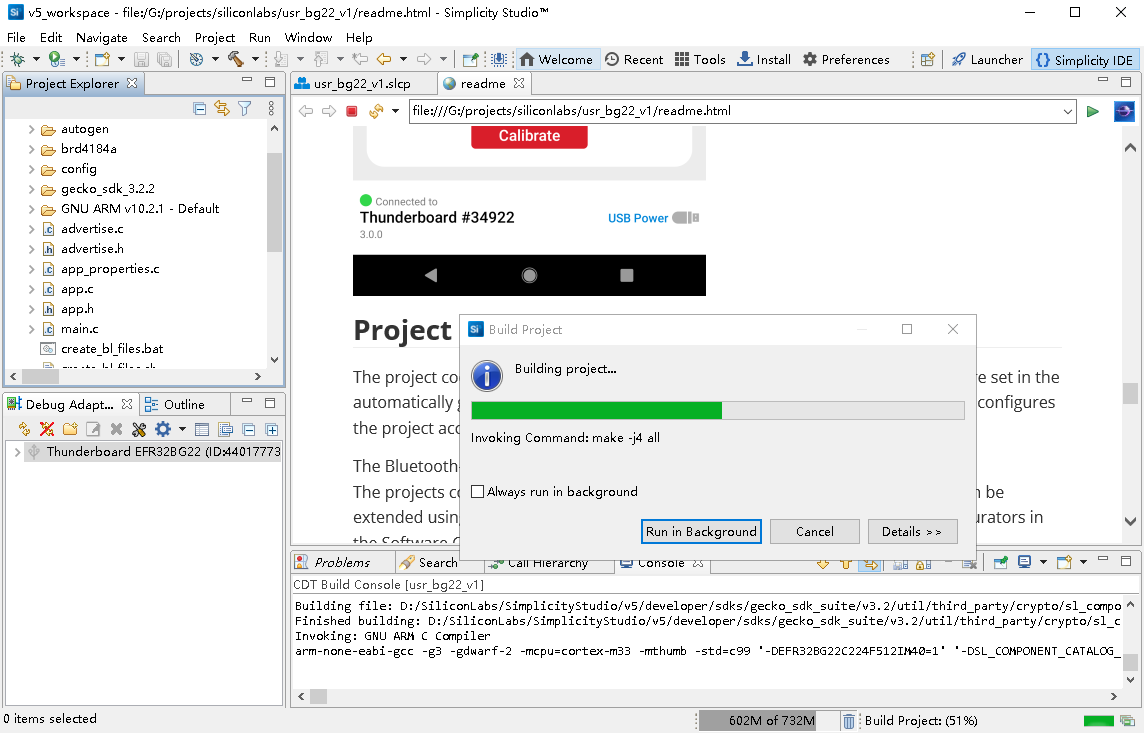
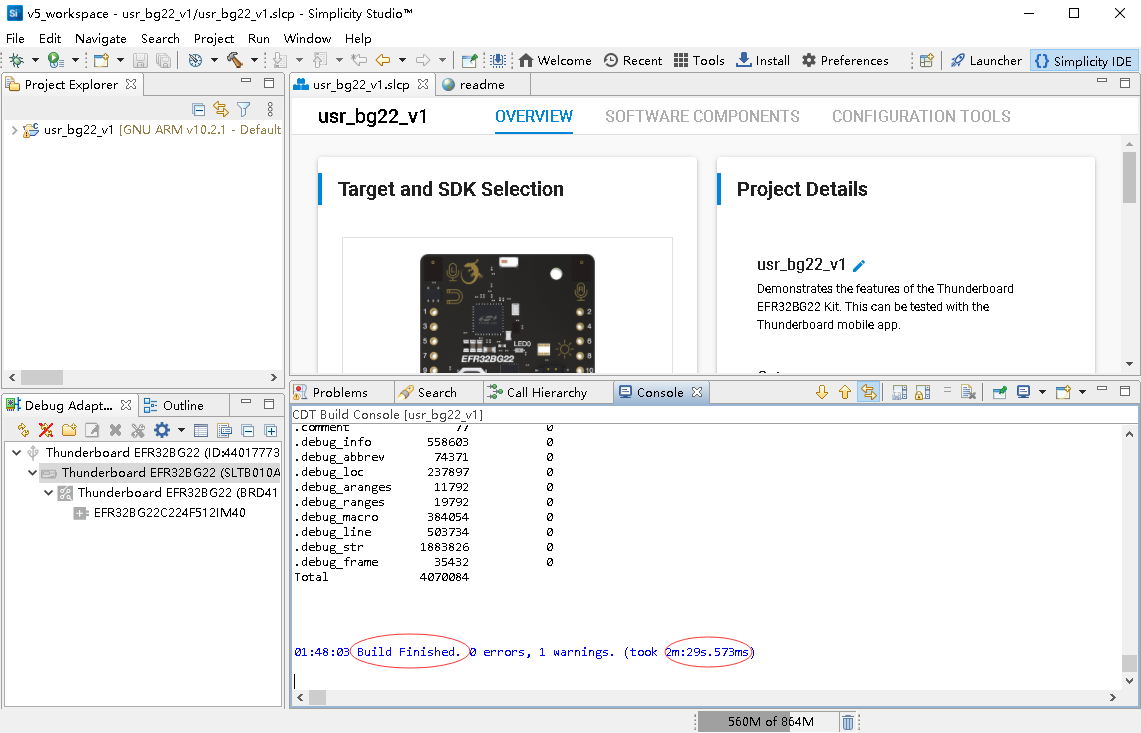
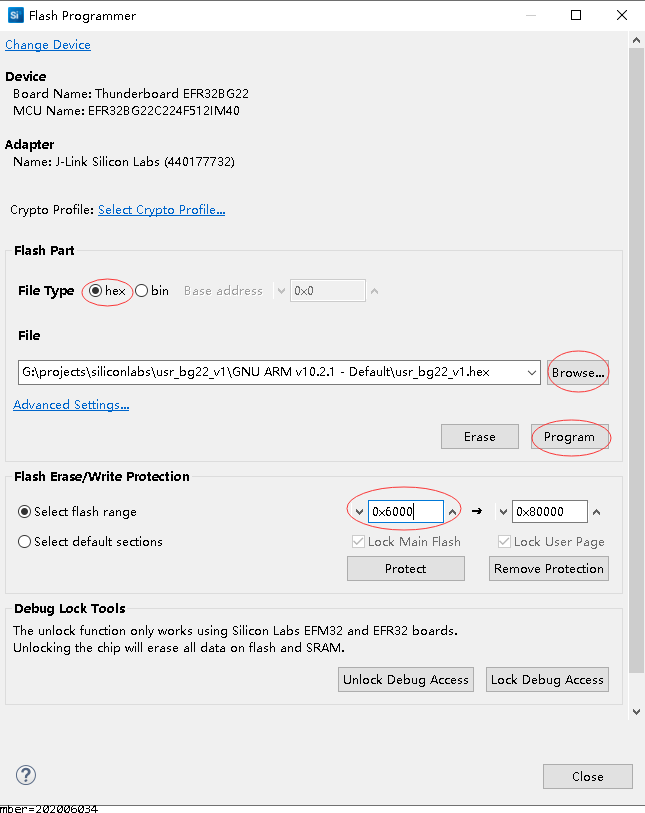
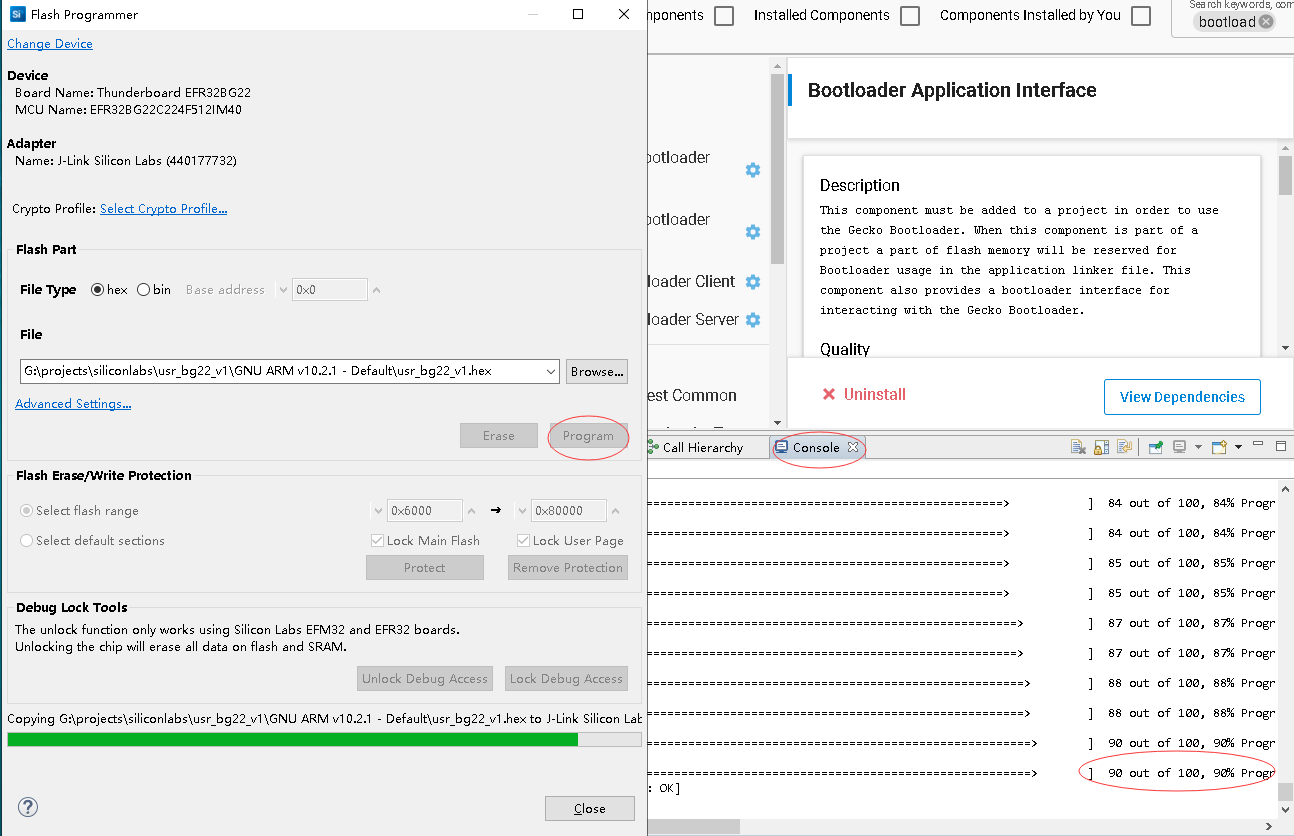
[I] Thuderboard demo initialised
[I] sv = 3.031 svl = 3.031 i = 0.003 r = 0.072
[I] Bluetooth stack booted: v3.2.3-b273
[I] Bluetooth public device address: 84:2E:14:31:CA:5D通过simplicity 的下载按钮下载的只是应用,是不包含bootloader的,如果之前全片erase过,下载后是无法正常运行的。更新boot的方法就是重新下载一个带boot的,然后再重新更新应用,或者独立下载系统内置的默认bootloader。
在我们尝试 erase时,出现下面的问题:
DP write failed
Could not access Debug challenge interface解决:
参考官方论坛的解答,断开重连问题得以解决: https://silabs-prod.adobecqms.net/community/software/simplicity-studio/forum.topic.html/can_t_program_bgm220pc22hnamoduledpwritefaile-j6BP
进一步的原因,其实官方的文档里面有描述:
https://www.silabs.com/documents/public/training/wireless/bg22-thunderboard-workshop-out-of-the-box-thunderboard-example-project.pdf
Error: DP Write Failed - Press the Reset button on Thunderboard or unplug/replug then Flash again within 30 seconds.
The Thunderboard demo app which ships on the boards goes into a low energy mode (EM2) after 30 seconds. When the device is in EM2,
the debug interface is unavailable, and DP write fails. We can wake the device by resetting Thunderboard在烧录下载了我们自己编译的嵌入式版本后,我们接下来要用原厂配套的APP来测试各个功能,以确保我们手头的代码版本功能正常。


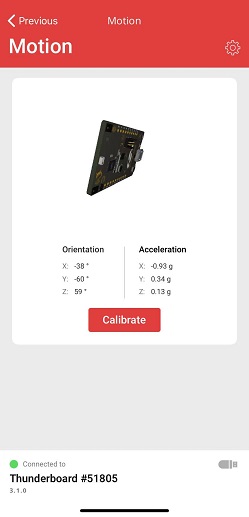
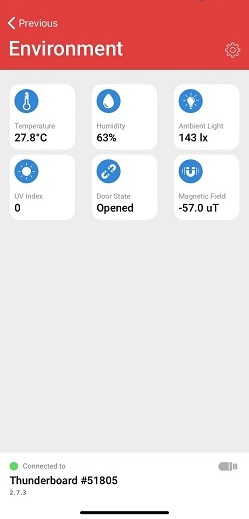
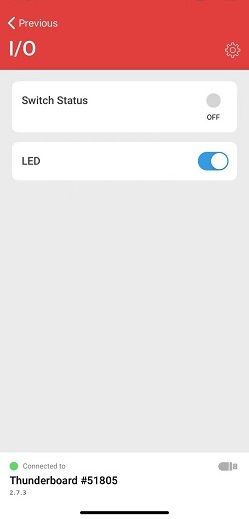
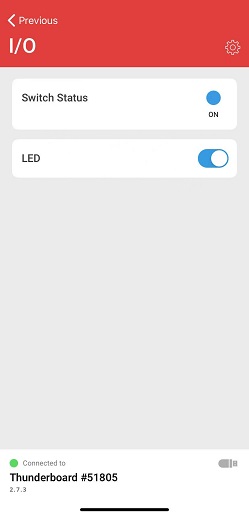
至此,我们编译的版本,在APP的各项测试中都正常通过,跟出厂的原装版本表现一致,也就证明了我们这套代码以及环境的可用性和正确性,接下来我们就可以放心基于这套驱动和参考代码来构建我们自己的功能产品了。
不论是从芯片支持的外围传感器的驱动丰富性,还是从开发IDE Simplicity和配套APP的易用和完备角度来看,EFR32BG22芯片及其开发SDK套件都是低功耗蓝牙物联网解决方案的极具竞争力选择,其芯片价格在一线品牌中也很有竞争力,具有极高性价比,值得我们深入挖掘和研究。
BG22带蓝牙协议栈的版本是需要bootloader的。如果开发过程中我们不小心把bootloader覆盖了或者擦除了,怎么重新烧录?
有2种方法:
第1种在simplicity中可以一键完成,所以我们不再赘述。我们接下来重点详细介绍第2种方法。
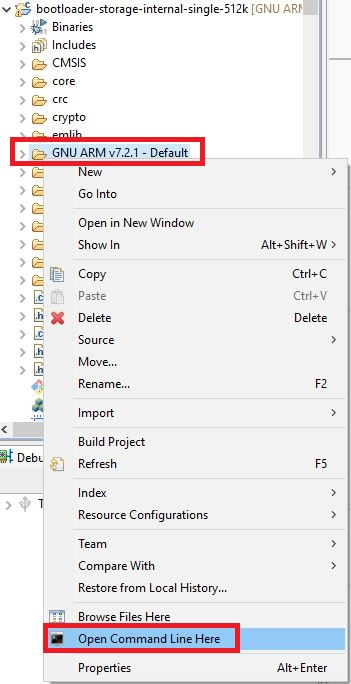
commander flash D:\SiliconLabs\SimplicityStudio\v5\developer\sdks\gecko_sdk_suite\v3.2\platform\bootloader\sample-apps\bootloader-storage-internal-single-512k\efr32mg22c224f512im40-brd4182a\bootloader-storage-internal-single-512k.s37这里需要需要注意环境变量的问题,如果提示不能识别commander,就需要自己手动配置。我们这里使用的是系统默认的boot,如果用自己的,注意改成实际boot项目的路径。
成功后提示如下:

The serial format is 115200 bps, 8 bits, no parity, and 1 stop bit by default.
实际是先整片擦除,然后自动重新烧录了bootloader
commander convert bootloader-uart-bgapi_BG21_test.s37 your_application.s37 -o app+bootloader.s37合并bootloader和应用的命令在UG162文档描述如下:
5.5.1 Combine Two Files
Converts two files with different file formats into one specified output file. Command Line Syntax:
$ commander convert <filename> <filename> [--address <address>] --outfile <filename>注意:需要指定转换文件的路径,如果不指定路径,需要把转换的文件放到commander软件同一路径下。
今天国庆有空,所以抽空定位下之前发现的七牛头像文件接口访问失效的问题。接口以前是正常的,中间无代码修改,最近发现有错误日志,同时app头像加载异常。
经过服务器业务日志分析,是php 的readfile函数失效。
在出问题的服务器用wget 和curl测试都无法很快下载,需要等非常长时间,但是我本地的浏览器正常,能很快访问。所以接口失败就应该是超时导致的。刚开始没有头绪,以为是七牛的安全相关的问题,后面根据wget的日志,发现每次都优先解析的是ipv6地址,于是怀疑可能是ipv6的问题。
于是禁用服务器的ipv6:
编辑文件/etc/sysctl.conf,
vi /etc/sysctl.conf
添加下面的行:
net.ipv6.conf.all.disable_ipv6 =1
net.ipv6.conf.default.disable_ipv6 =1
如果你想要为特定的网卡禁止IPv6,比如,对于enp0s3,添加下面的行。
net.ipv6.conf.enp0s3.disable_ipv6 =1
保存并退出文件。
执行下面的命令来使设置生效。
sysctl -p再次尝试wget,curl,皆正常,于是测试php接口,恢复正常。
ios:15.0.1
xcode:13.0
在苹果地图页面手势缩放时,会显示:
[VKDefault] Zero Length edge on polygon boundary然后多次反复缩放,一直触发这个日志,然后系统就会提示内存泄露 memory leak,然后崩溃。
==14901==ERROR: AddressSanitizer: allocator is out of memory trying to allocate 0x110 bytes
==14901==FATAL: AddressSanitizer: internal allocator is out of memory trying to allocate 0x50 bytes
warning: could not execute support code to read Objective-C class data in the process. This may reduce the quality of type information available.
AddressSanitizer report breakpoint hit. Use 'thread info -s' to get extended information about the report.暂时没有办法,只能等新版本再观察了,如果有解决方案的朋友希望留言,谢谢
Failed to prepare device for development这个是xcode和ios设备的版本不匹配导致。需要更新xcode的设备支持包,
以下为例子,因为系统是不断升级的,具体自己对照下:
DAO: Decentralized Autonomous Organization(去中心化自治组织)
瑞波币(XRP): 是瑞波(Ripple)系统内的流动性工具,是一个桥梁货币,是各类货币之间兑换的中间品
TRX: 波场币发行 波场币是由波场基金会发行的基于波场协议的主网货币,简称TRX。 TRX是TRON区块链上账户的基本单位,所有其他代币的价值均从TRON价值衍生出来,TRX也是所有基于TRC标准代币的天然桥梁货币。
TRC20:类似ERC20,是一种基于波场的转帐协议或者通道.
DXO: DeepSpace Token
L1,L2: https://www.jianshu.com/p/2c957b67fa19
其中第 0 层对应 OSI 模型的底层协议,大致包括物理层、数据链路层、网络层和传输层。第一层(Layer 1)大致包括数据层、共识层和激励层。
而第 2 层(Layer 2)则主要包括合约层和应用层。
按照这个维度来划分,像我们所熟悉的比特币网络、以太坊主网等主流公链都属于 Layer 1 的范畴。只不过,由于在当前众多的公链项目中,以太坊是运行智能合约、DAPP 最多的公链,也是锁仓资产价值和日均交易量最大的公链,所以在有关以太坊网络 Layer1 和 Layer2 不同扩容方案的讨论也是最多的,所以在本文中,如没有特殊说明,所提到的 Layer1 和 Layer2 一般以以太坊为主。
通俗来说,在以太坊网络中,Layer 1 的主要作用就是确保网络安全、去中心化及最终状态确认,做到状态共识,并作为一条公链网络中可信的“加密法院”,通过智能合约设计的规则进行仲裁,以经济激励的形式将信任传递到 Layer2 上;而 Layer2 则以追求更高效的性能为终极目标,从上面区块链技术逻辑架构示意图中,我们可以看到,作为第二层网络,可以替 Layer1 承担大部分计算工作,近年来,不少项目都是基于 Layer2 搭建的,从而将交易行为从主链上分离出来,降低一层网络的负担,提高业务处理效率,从而实现扩容。在这个过程中,Layer2 虽然只做到了局部共识,但是基本可以满足各类场景的需求。
目前行业内比较贴切的是将 Layer1 和 Layer2 的关系和中央银行与商业银行的关系来类比:把 Layer1 承担着中央银行的角色,而 layer2 则是各大商业银行。
在现行主流的金融系统中,所有的资产都必须在中央银行结算,而具体的流通过程可以同时发生在中央银行和商业银行。因为如果所有人都去央行结算的话,势必会发生业务拥堵的情况,更好的解决办法当然是由商业银行来先处理大量交易业务,然后由各个商业银行和中央银行结算一次整体业务,这样才能使得整个金融系统更加高效有序的运转起来。
所以从中我们能够得到的启示就是,对于在以太坊网络中存在的交易拥堵、手续费居高不下的问题,一个可行的解决方案就出炉了——将以太坊的资产存入 Layer2,之后的资产流动交易环节都在 Layer2 上进行,只把最终结算过程放到 Layer1 上就可以了.celr: celer network 代币,属于l2技术,主打链下链上结合,发挥链下方案的性能优势
ren: republic protocol 代币,主打私密撮合交易
rune: THOR chain的代币,主打快速结算
dydx:基于ERC20的dydx exchange平台的token,主打deFi和低手续费
maxLevel,subMaxLevel是docsify中的两个重要的参数,用来控制整个文档站左侧导航菜单的层级。
maxLevel:控制着左侧的菜单的总层级.
subMaxLevel:表示由文档内容中的标题自动生成菜单的级别,从第一级起算。例如subMaxLevel取2,表示一共两级,所以实际只显示第二级(##),因为第一级默认跟外层的入口同级,显示外层的名字。
maxLevel>=1
subMaxLevel>=1 && subMaxLevel<maxLevel
我们知道要实现https,MQTT等协议时,要求通讯安全,客户端就必须实现tls证书的支持。
但是日常我们打来电脑和手机浏览器访问https网站,好像并不需要关注tls的问题?
答案是因为浏览器厂商已经帮助我们兼容好了,但当你要通过嵌入式IOT设备或者单片机实现https访问的时候,你就需要处理TLS证书的问题了。
因为ESP32的开源代码比较清晰简洁,所以我们今天的讲解,以ESP32为硬件平台。其他硬件也是类似的原理,你只要实现自己的过程,替换底层的socket接口就可以实现类似的效果。
此文通过对关键代码的详细讲解,说明在ESP32下支持TLS证书的实现原理和过程。以此原理和过程作为参考,用户也可以实现其他嵌入式硬件和单片机的TLS证书支持,因为ESP的证书的内容和代码都是源码可见的,在弄懂了后就可以很好的移植和仿制。
官方的例子见 \examples\protocols\https_request,举例了三种支持TLS的方式:
https_get_request_using_crt_bundle();
https_get_request_using_cacert_buf();
https_get_request_using_global_ca_store();第一种是cert bundle方式,这个是今天我们重点的讲解。后两种就是使用用户指定的证书的方式,代码非常简单,就不展开了,今天主要介绍 cert bundle的方式。把cert bundle方式弄清楚了,后面两种也就清楚了,因为就是等于是cert bundle 方式的简化,简化了证书的创建,匹配和校验过程。
esp32 针对TLS的场景提供了x509 Certificate Bundle的实现支持,其可以简单理解为 x509证书集合。
关于x509 Certificate Bundle的详细介绍,可以参看:https://docs.espressif.com/projects/esp-idf/zh_CN/latest/esp32/api-reference/protocols/esp_crt_bundle.html 。
原文已经讲的非常清楚了,我们就不赘述了,今天只重点关注源码细节。
上面简述了整个过程,接下来我们将针对上面的步骤,对关键源码进行解析说明。
外层调用:
if (s_crt_bundle.crts == NULL) {
ret = esp_crt_bundle_init(x509_crt_imported_bundle_bin_start);
}参数 x509_crt_imported_bundle_bin_start 对应的值为 asm("_binary_x509_crt_bundle_start")
这个asm对象表示一段汇编代码,作用是返回x509对象数据地址,这个对象是通过python工具将cacrt_all.pem打包成二进制文件的,具体汇编的内容,可以自己参见 build目录下的 x509_crt_bundle.S汇编文件。
里层函数实现,解析注释:
static esp_err_t esp_crt_bundle_init(const uint8_t* x509_bundle)
{
// 根据包头的两个字节获取证书个数
s_crt_bundle.num_certs = (x509_bundle[0] << 8) | x509_bundle[1];
s_crt_bundle.crts = calloc(s_crt_bundle.num_certs, sizeof(x509_bundle));
if (s_crt_bundle.crts == NULL) {
ESP_LOGE(TAG, "Unable to allocate memory for bundle");
return ESP_ERR_NO_MEM;
}
const uint8_t* cur_crt;
cur_crt = x509_bundle + BUNDLE_HEADER_OFFSET;
ESP_LOGW(TAG, "cert num:%d", s_crt_bundle.num_certs);
// 根据个数一个一个的来偏移获取每个证书的内容
for (int i = 0; i < s_crt_bundle.num_certs; i++) {
s_crt_bundle.crts[i] = cur_crt;
// 每个证书前面4个字节是长度信息
size_t name_len = cur_crt[0] << 8 | cur_crt[1];
size_t key_len = cur_crt[2] << 8 | cur_crt[3];
ESP_LOGW(TAG, "cert name len:%d,key len:%d", name_len, key_len);
// 根据长度进行每个证书的偏移
cur_crt = cur_crt + CRT_HEADER_OFFSET + name_len + key_len;
}
return ESP_OK;
}这段代码的作用就是 将入参的cert bundle 地址内存,根据数据结构定义{BUNDLE_HEADER_OFFSET,{name_len,key_len, name,key}}反序列化成cert结构数组对象 s_crt_bundle。
截止本文撰写日期,esp32 实现的这个x509 cert bundle 支持135个根证书,几乎支持了全球所有的证书。
mbedtls_x509_crt_init(&s_dummy_crt);
mbedtls_ssl_conf_ca_chain(ssl_conf, &s_dummy_crt, NULL);这个空证书的作用主要是承载访问服务器时获取的服务器证书特征,这个特征会通过回调的方式传给 mbedtls_ssl_conf_verify 函数参数。
代码如下,解析见注释:
int esp_crt_verify_callback(void* buf, mbedtls_x509_crt* crt, int depth, uint32_t* flags)
{
mbedtls_x509_crt* child = crt;
/* It's OK for a trusted cert to have a weak signature hash alg.
as we already trust this certificate */
uint32_t flags_filtered = *flags & ~(MBEDTLS_X509_BADCERT_BAD_MD);
if (flags_filtered != MBEDTLS_X509_BADCERT_NOT_TRUSTED) {
return 0;
}
if (s_crt_bundle.crts == NULL) {
ESP_LOGE(TAG, "No certificates in bundle");
return MBEDTLS_ERR_X509_FATAL_ERROR;
}
ESP_LOGD(TAG, "%d certificates in bundle", s_crt_bundle.num_certs);
size_t name_len = 0;
const uint8_t* crt_name;
// start 和 end 是证书数组的index。这里实现的是二分查找算法,说明cert bundle
// 数组的名字是增加了排序特征的,具体细节,需要查看python的打包工具的实现代码。
bool crt_found = false;
int start = 0;
int end = s_crt_bundle.num_certs - 1;
int middle = (end - start) / 2;
/* Look for the certificate using binary search on subject name */
while (start <= end) {
name_len = s_crt_bundle.crts[middle][0] << 8 | s_crt_bundle.crts[middle][1];
crt_name = s_crt_bundle.crts[middle] + CRT_HEADER_OFFSET;
int cmp_res = memcmp(child->issuer_raw.p, crt_name, name_len);
if (cmp_res == 0) {
crt_found = true;
break;
} else if (cmp_res < 0) {
end = middle - 1;
} else {
start = middle + 1;
}
middle = (start + end) / 2;
}
// 二分查找结束
// 校验证书合法性
int ret = MBEDTLS_ERR_X509_FATAL_ERROR;
if (crt_found) {
size_t key_len = s_crt_bundle.crts[middle][2] << 8 | s_crt_bundle.crts[middle][3];
ret = esp_crt_check_signature(child, s_crt_bundle.crts[middle] + CRT_HEADER_OFFSET + name_len, key_len);
}
if (ret == 0) {
ESP_LOGI(TAG, "Certificate validated");
*flags = 0;
return 0;
}
ESP_LOGE(TAG, "Failed to verify certificate");
return MBEDTLS_ERR_X509_FATAL_ERROR;
}代码很简单,注释中已经说了,就是一个二分查找过程。
相关代码在上面的部分已经注释过了,就是esp_crt_check_signature函数。校验的细节,感兴趣的朋友可以自己查看此函数源码。
写请求过程:
do {
ret = esp_tls_conn_write(tls, REQUEST + written_bytes, sizeof(REQUEST) - written_bytes);
if (ret >= 0) {
ESP_LOGI(TAG, "%d bytes written", ret);
written_bytes += ret;
} else if (ret != ESP_TLS_ERR_SSL_WANT_READ && ret != ESP_TLS_ERR_SSL_WANT_WRITE) {
ESP_LOGE(TAG, "esp_tls_conn_write returned: [0x%02X](%s)", ret, esp_err_to_name(ret));
goto exit;
}
} while (written_bytes < sizeof(REQUEST));
esp_tls_conn_write根据长度来循环写。
读响应过程:
do {
len = sizeof(buf) - 1;
bzero(buf, sizeof(buf));
ret = esp_tls_conn_read(tls, (char*) buf, len);
if (ret == ESP_TLS_ERR_SSL_WANT_WRITE || ret == ESP_TLS_ERR_SSL_WANT_READ) {
continue;
}
if (ret < 0) {
ESP_LOGE(TAG, "esp_tls_conn_read returned [-0x%02X](%s)", -ret, esp_err_to_name(ret));
break;
}
if (ret == 0) {
ESP_LOGI(TAG, "connection closed");
break;
}
len = ret;
ESP_LOGD(TAG, "%d bytes read", len);
/* Print response directly to stdout as it is read */
for (int i = 0; i < len; i++) {
putchar(buf[i]);
}
putchar('\n'); // JSON output doesn't have a newline at end
} while (1);esp_tls_conn_read 循环读,直到链接关闭为止,跳出循环
释放 tls对象:
esp_tls_conn_delete(tls);好了,整个代码过程还是封装的非常干净和清晰的,如果你需要在自己的嵌入式系统中实现TLS证书过程,那么也可以仿照以上的过程,实现自己的bundle和匹配校验过程,并且可以根据实际需要定制和优化。
希望以上的分析,能帮你快速实现自己的TLS访问功能。
见官方的声明 https://letsencrypt.org/docs/dst-root-ca-x3-expiration-september-2021/
今年2021.9.30后,原有的DST RootCA X3就要过期了,改成ISRG Root X1。
对于浏览器用户基本不用担心,因为浏览器厂商自动做了支持。但是对于老旧的设备和一些嵌入式IOT设备等,就需要支持最新的证书,否则可能出现访问的问题。
idf.py menuconfigcomponent config -> log output -> Default log verbosity
显示目标链中的所有证书:
openssl s_client -showcerts -connect www.xxx.com:443 </dev/null当有多个子域名的时候,第一个不一定是想要的,所以自己根据CN来判断到底是哪组证书。然后自己截取 "-BEGIN CERTIFICATE-" "-END CERTIFICATE-" 之间的部分。
如果直接取第一个:
openssl s_client -showcerts -connect www.xxx.com:443 </dev/null |sed -ne '/-BEGIN CERTIFICATE-/,/-END CERTIFICATE-/p' > test.cert目标环境:unraid
玩nas的都知道,ddns是必不可少的服务,让你能在互联网访问家里服务器的所有服务。
之前用的是一个免费的ddns,但是一个月要手动激活确认一次,觉得很麻烦。其次测试发现ip的同步时效有问题,时间久了就导致服务地址不可用(中间做了proxy,目前还没有最终确认是nginx的问题,还是这个ip失效的问题,待换了此新方案后确认)。
补充:这问题应该是nginx的proxy_pass的dns缓存问题。
简单的搜了下,目前有宝塔,群晖等方案,但考虑到方案的通用性,还是决定直接用原生cron的方案,而实际操作下来,也非常方便。
dnspod目前支持的工具包地址: https://github.com/rehiy/dnspod-shell
1. 编辑ddnspod.sh,分别修改/your_real_path/ardnspod、arToken和arDdnsCheck为真实信息
2. 运行ddnspod.sh,开启循环更新任务;建议将此脚本支持添加到计划任务;crontab -e
在末尾添加:
# Run minute cron jobs at every minutes after the hour:
* * * * * /xxx/dnspod-shell/ddnspod.sh 1> /dev/null路径改成自己实际的。
如果发现127.0.0.1变成实际的ip了,说明脚本和定时任务生效了。
build.gradle的内容都是由系统配置自动生成的,如果有相关报错,先确认系统配置。
grandle配置。file -> project structure -> project。
dependecies的配置,目前看是grandle的插件来自动更新这部分内容的,需要确认grandle插件的正确安装:
dependencies {
classpath 'com.android.tools.build:gradle:4.2.2'
classpath 'com.google.gms:google-services:4.3.3'
}app 签名管理:file -> project structure -> Modules -> Signing configs
allprojects {
repositories {
google()
jcenter()
}
}goole地图的支持:通过在dependencies添加实现:
dependencies {
implementation fileTree(dir: 'libs', include: ['*.jar'])
implementation 'com.google.android.gms:play-services-maps:12.0.1'
implementation 'com.google.maps.android:android-maps-utils:0.5+'
}具体版本,需要自己实际调整。
参考nordic官方数据:
Certificates, Identifiers & Profiles,下载 Apple Push Services文件,生成的是 apns.cer,将cer双击导入到苹果系统。
从钥匙串中导出p12文件,证书和证书的key,注意设置安全密码:

通过命令行开始生成
cert:
openssl pkcs12 -clcerts -nokeys -out apns_cert.pem -in apns_cert.p12
key:
openssl pkcs12 -nocerts -out apns_cert_key.pem -in apns_cert_key.p12这个过程会提示你输入之前的文件的密码,以及新生成的文件的密码,一定要区分清楚,因为后面的程序调试是需要生成文件的密码的。
将两个pem合成一个
cat apns_cert.pem apns_cert_key.pem > ck.pem验证
开发证书:
openssl s_client -connect gateway.sandbox.push.apple.com:2195 -cert apns_cert.pem -key apns_cert_key.pem
量产证书:
openssl s_client -connect gateway.push.apple.com:2195 -cert apns_cert.pem -key apns_cert_key.pem
如果验证成功,内容结尾显示如下:
SSL-Session:
Protocol : TLSv1.2
Cipher : DES-CBC3-SHA
Session-ID:
Session-ID-ctx:
Master-Key: xxx
Start Time: 1627218051
Timeout : 7200 (sec)
Verify return code: 0 (ok)Verify return code: 0 (ok),说明成功。
如果你恰好在研究admob,当你开通admob时,提示你有ads绑定无法开通。
那么如何将ads从google账号下解除呢:
httpd_txrx: httpd_resp_send_err: 431 Request Header Fields Too Large - Header fields are too long for server to interpret在menuconfig中,调整HTTPD_MAX_REQ_HDR_LEN 的值:
menuconfig=>component config=>HTTP server=>max http request header leagth
官方其实已经对此问题做了说明,\examples\protocols\http_server\simple\README.md
If the server log shows "httpd_parse: parse_block: request URI/header too long", especially when handling POST requests, then you probably need to increase HTTPD_MAX_REQ_HDR_LEN, which you can find in the project configuration menu (`idf.py menuconfig`): Component config -> HTTP Server -> Max HTTP Request Header Length相关源码路径: \examples\system\console\components\cmd_system
这个框架实际就是一个现成构架好的命令字,参数以及回调函数的框架,只要我们按照规范填写对应的参数,就能实现一个完整的console命令。
// 第1步:
/*参数段设置*/
// 第2步:
/*命令结构体配置*/
// 第3步:将命令结构体插入命令序列
ESP_ERROR_CHECK(esp_console_cmd_register(&cmd));我们找一个例子说明,其他的都是类似的步骤。
int num_args = 1;
deep_sleep_args.wakeup_time = arg_int0("t", "time", "<t>", "Wake up time, ms");
#if SOC_PM_SUPPORT_EXT_WAKEUP
deep_sleep_args.wakeup_gpio_num = arg_int0(NULL, "io", "<n>", "If specified, wakeup using GPIO with given number");
deep_sleep_args.wakeup_gpio_level = arg_int0(NULL, "io_level", "<0|1>", "GPIO level to trigger wakeup");
num_args += 2;
#endif
deep_sleep_args.end = arg_end(num_args);deep_sleep_args 是用户创建的结构体,这个根据实际需要创建,例子中用的是int做参数,所以结构体主要是 arg_int, 以此类推,你可以选择arg_rem、arg_lit、arg_db1、arg_str等等。
这个结构体定义的最后一个成员是固定的 end,用来限制参数的个数。
arg_int0:表示当前字段最多一个参数,可以为空,类型为int。
arg_int1:标识当前为一个必填字段,类型为int。
arg_intn:以此类推。
如果是其他类型,就有其他类似arg_xxx的参数构造函数。
我们具体以上面的内容为例子
arg_int0("t", "time", "<t>", "Wake up time, ms");其中有4个成员,分别是:
源码例子:
const esp_console_cmd_t cmd = {
.command = "deep_sleep",
.help =
"Enter deep sleep mode. "
#if SOC_PM_SUPPORT_EXT_WAKEUP
"Two wakeup modes are supported: timer and GPIO. "
#else
"Timer wakeup mode is supported. "
#endif
"If no wakeup option is specified, will sleep indefinitely.",
.hint = NULL,
.func = &deep_sleep,
.argtable = &deep_sleep_args
};其中 command、help、hint、func、argtable 是系统的固定定义,分别表示:
从上面的内容可以知道,我们要设计自己的命令行需要做一下工作:
到这里,我们就实现了自己的命令行,是不是很简单,主要的工作量都在准确实现参数列表和回调上。
最近完成了esp32 自动扫描nordic设备的广播名称,并跟nordic uart server通讯的功能。
esp32 :ble uart client, gatt_client
nordic:ble uart server (NUS), gatt_server
说明:因为通讯的交互过程跟char的数量以及属性有关系的,有几个char,是只读还是读写等,这些都对应不同的交互流程。 所以以下的内容过程就是针对nordic NUS的特征的而撰写的,如果你自己的设备有所不同,要灵活调整,不可生搬硬套,重要的是理解gatt本质。
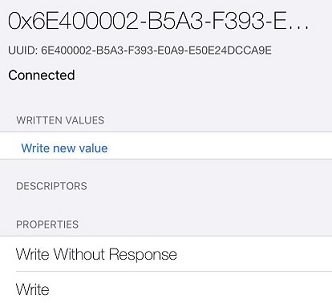
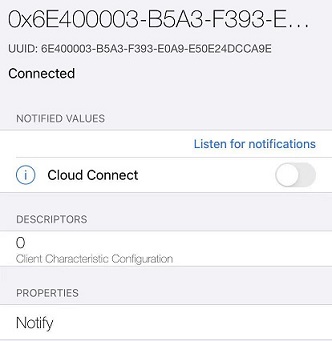
说明:ca9e 是nordic的蓝牙串口服务 NUS,下面有两个 char。 RX uuid 是0002,属性是write 和write without response, TX uuid 是0003,属性是notify。
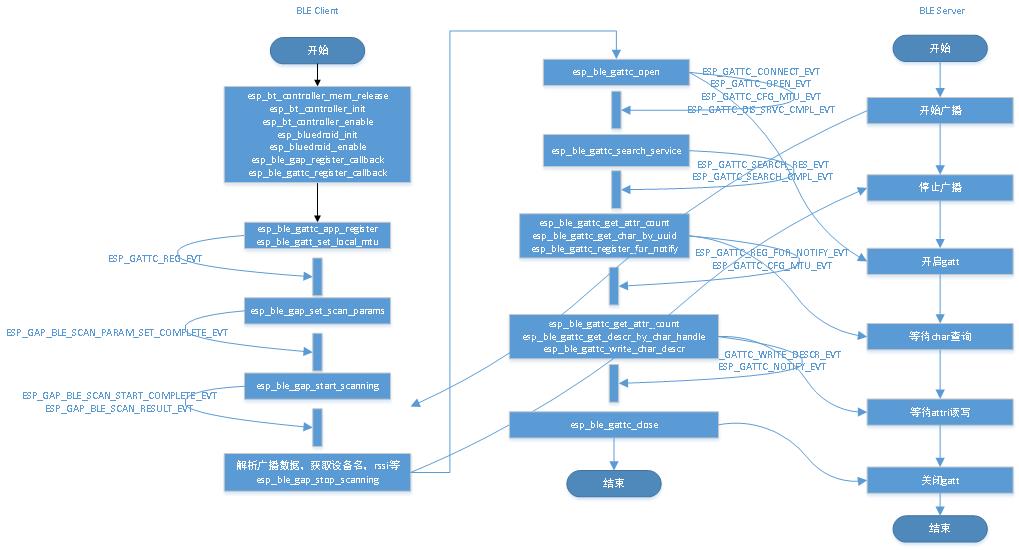
In the era of Internet of Things(IoT), wireless communication is getting increasingly popular in everyday life. In the world of IoT devices, ESP32 is a popular low-cost System on Chip (SoC) microcontroller with built-in hybrid WiFi and Bluetooth chips by Espressif Systems. Because of its robust design and ultra-low power consumption, it has become so popular in IoT applications. But when we talk about IoT applications, security in IoT will come to our mind for data safety and secure connection. ESP32 supports X.509 certificate-based mutual authentication for HTTPs, IoT cloud (AWS-IoT, Azure, Google Firebase, etc.) authentication, and data communications. Over the Internet, ESP32 also gives us the data security for stored data into FLASH memory and Boot Sectors to prevent the data from being stolen. Today we talk about the ESP32 security features, mainly related to of Boot sectors. The two main security features on ESP32 are called Secure-Boot and flash security, also known as Flash-Encryption.
The ESP32 has a 1024-bits One-Time-Programmable (OTP) memory block. This OTP memory block is divided into 4-block of 256-bits each.
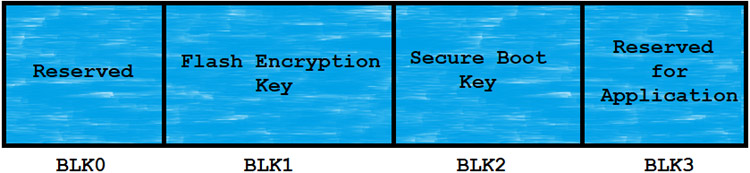
These blocks of memory store the keys of the Flash encryption and Secure Boot. Because of the OTP memory block, there is no software present to read out those memory blocks. One and only ESP32 hardware can read and validate the Security features.
ESP32 Flash Encryption is a security feature for the ESP32 provided by the ESP-IDF by Espressif System to protect the flash memory. Flash encryption is encrypting the contents of ESP32’s SPI flash memory and when this feature is enabled, the following types of data are encrypted by default:
idf.py menuconfigAfter open the ESP32 project config menu, now navigate to
“Security Features” -->
“Enable flash encryption on boot” -->
“Enable usage mode (Development(NOT SECURE))” / “Enable usage mode (Release)”In flash encryption there are two modes:
When the flash encryption is enabled, the binaries of the current code flash into the ESP32’s memory as a plain text file. But after completion of the flash process, on the first boot of the ESP32, the device itself encrypted each and every upper mention partition, one by one by using the AES flash encryption key which is stored into the eFUSE-BLK1 at the time of flash. After encrypting the partition the ESP32 device restarted itself and processed with the programmed logic.
The ESP32’s flash execution process decrypts the flash memory data when the ESP32’s execution unit tries to read and for the writing process, the flash execution process encrypts the data before writing into the flash memory.
The ESP32 Secure-boot is a security feature, which provides security to run correct applications on ESP32 hardware. When secure boot is enabled, each and every flash memory’s binaries [Software bootloader & Application firmware] are verified before loading with the RSA-3072 based Secure-boot’s signature keys. We can call the Secure-boot a “Guardian of The ESP32”.
For enabling the Flash Encryption, in the same steps we can enable the Secure-boot from the project menuconfig.
“Security Features” -->
“Enable hardware Secure Boot in bootloader”When the ESP32 device is booted up, then ESP32 hardware’s trusted rom or we said the 1st stage bootloader runs verification with RSA-3072 based secure-boot key on the software bootloader and then the software bootloader verifies the application firmware with the same signature key and start the application.
The ESP32 comes with a secure environment [Secure-boot & Flash-Encryption], which we need to enable while flashing the code. For more security, we need to enable both of them.
copy /usr/share/zoneinfo/xxx/xxx to /etc/localtime
原因:
为什么设置了时区以后,已经运行的程序在使用localtime函数调用时没有使用新时区呢?这个可以通过glibc的源码来回 答。localtime等涉及到本地所在时区的函数在调用的时候会先调用tzset这个函数,这一点可以通过tzset函数的manpage看出来。 tzset完成的工作是把当前时区信息(通过TZ环境变量或者/etc/localtime)读入并缓冲。事实上tzset在实现的时候是通过内部的 tzset_internal函数来完成的,显式的调用tzset会以显式的方式告知tzset_internal,而单独调用localtime的时候 是以隐式的方式告知tzset_internal,前者将强制tzset不管何种情况一律重新加载TZ信息或者/etc/localtime,而后者则是 只有在TZ发生变化,或者加载文件名发生变化的时候才会再次加载时区信息。因此,如果只是/etc/localtime的内容发生了变化,而文件名" /etc/localtime"没有变化,则不会再次加载时区信息,导致localtime函数调用仍然以老时区转换UTC时间到本地时间。
解决方法:在调用localtime之前调用tzset,则可强制刷新时区信息执行
ALTER TABLE tbl_name IMPORT TABLESPACE;
提示
Table 'xxx.xxx' doesn't exist in engine
先检查是不是真的不存在,其实是刚手动创建的,所以不是这个问题。
再排查,发现其中的一种错误:
覆盖或者导入的ibd文件,没有给予正确的用户归属权限,用chown设置下,就正常了
system:mac air 11.4beta
xcode:12.4 12D4e
iphone:XR 14.6
在xcode,手机出现“Unsupported OS version”,导致无法下载调试。
原因是当前系统和硬件下,xcode就本限制在了当前版本,无法升级到最新的,导致无法支持最新的手机版本。
参考:
因为原贴已经说的很清楚了,建议直接看原贴,如果想偷懒可以直接看以下总结步骤:
{kind=link}
{kind=link}